Protected: 你那天鹅颈,初见便令人沉醉的优雅,是我此生最眷恋的风景;你那天鹅颈,素简的线条在此化作最纯粹的优雅。
Enter your password to view comments.
根据德国《居留法》(AufenthG)第51条第2款,针对在德居住超过15年或配偶是德国人的长居持有者,存在豁免“离境6个月自动失效”的特别规定。
1 针对在德国合法居住超过15年的人士
如果您持有长居(Niederlassungserlaubnis),且同时满足以下两个条件,离开德国后长居不会失效:
居住时间: 您已在德国合法居住至少 15年(时间计算从首次获得合法居留算起,不仅是拿到长居后的时间)。
生活保障(最关键点):
您的生活来源必须是有保障的(Lebensunterhalt gesichert)。这意味着即使您长期居住在国外,也必须证明有足够的资金支持(如养老金、资产收入、存款等)。
注意: 如果您依赖德国的社会救济金(如Bürgergeld),则不享受此豁免。
2 针对德国公民的配偶
如果您持有长居,且满足以下条件,长居在离境后同样不会失效:
配偶身份:您的配偶必须拥有德国国籍。 婚姻关系:双方必须处于婚姻存续状态(eheliche Lebensgemeinschaft)。
特别提醒: 如果婚姻关系破裂(离婚或正式分居),此豁免权可能会立即终止,届时将重新适用“6个月离境失效”的规定。
!!! 至关重要的操作步骤 申请“不失效证明” !!!
虽然法律有此豁免,但系统可能会因为您长期离境自动判定长居失效。为了避免将来入境被拒或引起不必要的麻烦,请务必在离境前完成以下步骤:
前往外管局:
在离开德国前,联系居住地的外管局(Ausländerbehörde)。
提交申请: 申请开具一份“长居许可不失效证明” (Bescheinigung über das Nichterlöschen der Niederlassungserlaubnis)。
携带材料: 通常需要护照、长居卡、居住满15年的证明(或结婚证及配偶德国护照)、以及资金/养老金证明。
获得凭证: 拿到书面证明后,您即可放心长期离境。将来返回德国时,请出示该证明和护照。
法律依据: § 51 Abs. 2 Satz 1 & 2 AufenthG
德语申请信模版
您的姓名/现居地址/电话/邮箱
An die Ausländerbehörde (外管局地址,如不知道具体部门,写具体城市名即可,例如 Stadt Frankfurt am Main)
(日期: TT.MM.JJJJ)
Betreff: Antrag auf Ausstellung einer Bescheinigung über das Nichterlöschen der Niederlassungserlaubnis gemäß § 51 Abs. 2 AufenthG Mein Aktenzeichen / Geburtsdatum: (您的档案号,如果有的话,或者写出生日期)
Sehr geehrte Damen und Herren,
hiermit beantrage ich eine Bescheinigung darüber, dass meine Niederlassungserlaubnis auch bei einem geplanten Auslandsaufenthalt von mehr als sechs Monaten nicht erlischt.
Ich plane, mich ab dem (预计离境日期) für längere Zeit im Ausland aufzuhalten.
Begründung: (请从以下 A 和 B 中二选一,删除不适用的那个)
(选项 A:如果您在德居住已超过15年) Gemäß § 51 Abs. 2 Satz 1 AufenthG erlischt die Niederlassungserlaubnis nicht, da ich mich seit mindestens 15 Jahren rechtmäßig im Bundesgebiet aufhalte (seit 入德年份) und mein Lebensunterhalt gesichert ist.
(选项 B:如果您的配偶是德国人) Gemäß § 51 Abs. 2 Satz 2 AufenthG erlischt die Niederlassungserlaubnis nicht, da ich mit einem deutschen Staatsangehörigen, (配偶姓名), in ehelicher Lebensgemeinschaft lebe.
Anbei übersende ich Ihnen folgende Unterlagen zum Nachweis:
Kopie meines Reisepasses und der Niederlassungserlaubnis
(针对选项A) Nachweis über die Sicherung des Lebensunterhalts (z.B. Rentenbescheid, Vermögensnachweis) (中文备注:生活来源证明,如退休金通知、资产证明)
(针对选项B) Kopie der Heiratsurkunde und des Personalausweises meines Ehepartners (中文备注:结婚证复印件及配偶身份证复印件)
Ich bitte um eine schriftliche Bestätigung. Für Rückfragen stehe ich Ihnen gerne zur Verfügung.
Mit freundlichen Grüßen
签名
姓名打印体
使用小贴士:
二选一: 模版中“Begründung”部分有两个选项,请务必删除不符合您情况的那一段,只保留一段。
附件 (Anlagen):
如果是15年规定:重点在于证明您“有钱”,不需要领救济金。请附上养老金证明(Rentenbescheid)、银行存款证明或房产证明等。
如果是配偶规定:重点在于证明“婚姻关系”和“配偶国籍”。请附上结婚证和配偶的德国身份证/护照复印件。
发送方式: 建议先通过电子邮件发送给外管局,如果没有回复,再通过挂号信(Einschreiben)邮寄,以确保有据可查。
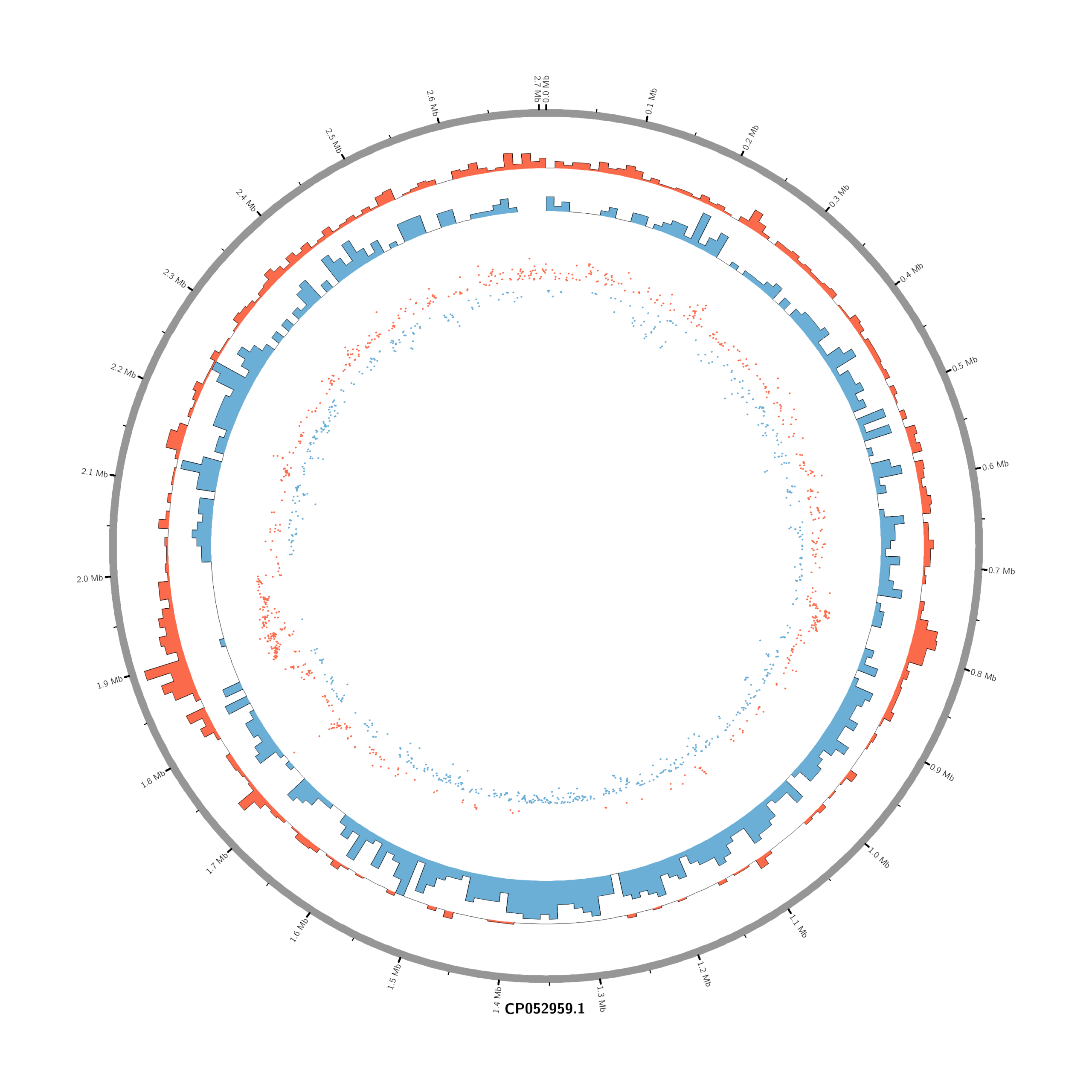
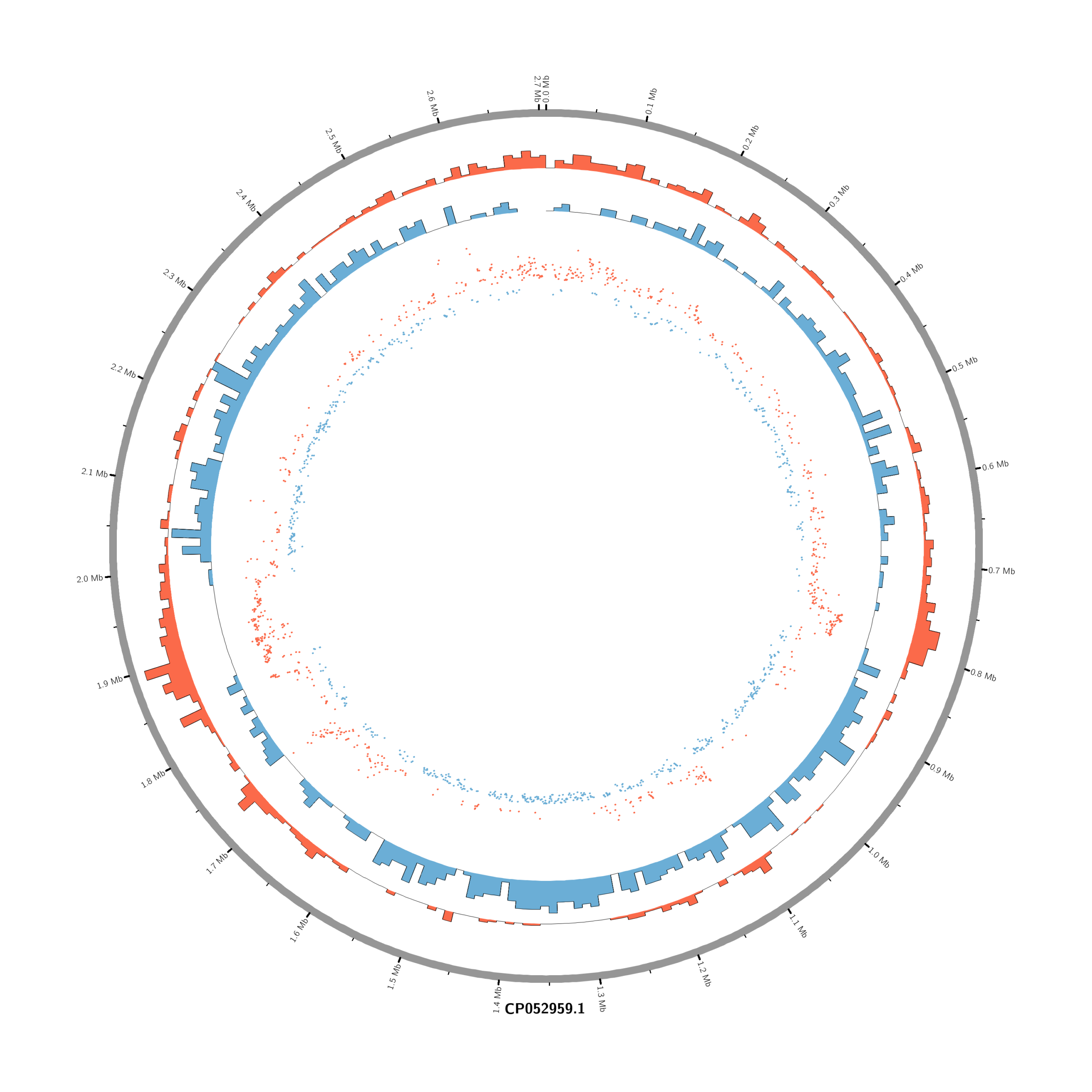
#Set the comparison condition in the R-script
comparison <- "Moxi_18h_vs_Untreated_18h"
# e.g.
# comparison <- "Mitomycin_18h_vs_Untreated_18h"
# comparison <- "Mitomycin_8h_vs_Untreated_8h"
# comparison <- "Moxi_8h_vs_Untreated_8h"
# comparison <- "Mitomycin_4h_vs_Untreated_4h"
# comparison <- "Moxi_4h_vs_Untreated_4h"
(r_env) Rscript make_circos_from_deseq.R
(circos-env) cd circos_Moxi_18h_vs_Untreated_18h
(circos-env) touch karyotype.txt (see the step2)
(circos-env) touch circos.conf (see the step3)
cp circos_Moxi_18h_vs_Untreated_18h/karyotype.txt circos_Moxi_8h_vs_Untreated_8h/
cp circos_Moxi_18h_vs_Untreated_18h/karyotype.txt circos_Moxi_4h_vs_Untreated_4h/
cp circos_Moxi_18h_vs_Untreated_18h/karyotype.txt circos_Mitomycin_18h_vs_Untreated_18h/
cp circos_Moxi_18h_vs_Untreated_18h/karyotype.txt circos_Mitomycin_8h_vs_Untreated_8h/
cp circos_Moxi_18h_vs_Untreated_18h/karyotype.txt circos_Mitomycin_4h_vs_Untreated_4h/
cp circos_Moxi_18h_vs_Untreated_18h/circos.conf circos_Moxi_8h_vs_Untreated_8h/
cp circos_Moxi_18h_vs_Untreated_18h/circos.conf circos_Moxi_4h_vs_Untreated_4h/
cp circos_Moxi_18h_vs_Untreated_18h/circos.conf circos_Mitomycin_18h_vs_Untreated_18h/
cp circos_Moxi_18h_vs_Untreated_18h/circos.conf circos_Mitomycin_8h_vs_Untreated_8h/
cp circos_Moxi_18h_vs_Untreated_18h/circos.conf circos_Mitomycin_4h_vs_Untreated_4h/
(circos-env) circos -conf circos.conf
#or (circos-env) /home/jhuang/mambaforge/envs/circos-env/bin/circos -conf /mnt/md1/DATA/Data_JuliaFuchs_RNAseq_2025/results/star_salmon/degenes/circos/circos.conf
#(circos-env) jhuang@WS-2290C:/mnt/md1/DATA/Data_JuliaFuchs_RNAseq_2025/results/star_salmon/degenes$ find . -name "*circos.png"
mv ./circos_Moxi_4h_vs_Untreated_4h/circos.png circos_Moxi_4h_vs_Untreated_4h.png
mv ./circos_Moxi_18h_vs_Untreated_18h/circos.png circos_Moxi_18h_vs_Untreated_18h.png
mv ./circos_Moxi_8h_vs_Untreated_8h/circos.png circos_Moxi_8h_vs_Untreated_8h.png
mv ./circos_Mitomycin_18h_vs_Untreated_18h/circos.png circos_Mitomycin_18h_vs_Untreated_18h.png
mv ./circos_Mitomycin_8h_vs_Untreated_8h/circos.png circos_Mitomycin_8h_vs_Untreated_8h.png
mv ./circos_Mitomycin_4h_vs_Untreated_4h/circos.png circos_Mitomycin_4h_vs_Untreated_4h.png
chr - CP052959.1 CP052959.1 0 2706926 grey karyotype = karyotype.txt
<ideogram>
<spacing>
default = 0.005r
</spacing>
radius = 0.80r
thickness = 20p
fill = yes
show_label = yes
label_radius = 1.05r
label_size = 30p
label_font = bold
label_parallel = yes
</ideogram>
# --- Wichtig: Schalter auf Top-Level, NICHT im
<ticks>-Block ---
show_ticks = yes
show_tick_labels = yes
<ticks>
# Starte direkt an der äußeren Ideogramm-Kante
radius = dims(ideogram,radius_outer)
orientation = out # Ticks nach außen zeichnen (oder 'in' für nach innen)
color = black
thickness = 2p
size = 8p
# kleine Ticks alle 100 kb, ohne Label
<tick>
spacing = 50000
size = 8p
thickness = 3p
color = black
show_label = no
</tick>
# große Ticks alle 500 kb, mit Label in Mb
<tick>
spacing = 100000
size = 12p
thickness = 5p
color = black
show_label = yes
label_size = 18p
label_offset = 6p
multiplier = 0.000001 # in Mb
format = %.1f
suffix = " Mb"
</tick>
</ticks>
<plots>
# Density of up-regulated genes
<plot>
show = yes
type = histogram
file = data/density_up.txt
r0 = 0.88r
r1 = 0.78r
fill_color = red
thickness = 1p
</plot>
# Density of down-regulated genes
<plot>
show = yes
type = histogram
file = data/density_down.txt
r0 = 0.78r
r1 = 0.68r
fill_color = blue
thickness = 1p
</plot>
# Scatter of individual significantly DE genes
<plot>
show = yes
type = scatter
file = data/genes_scatter.txt
r0 = 0.46r
r1 = 0.76r
glyph = circle
glyph_size = 5p
stroke_thickness = 0
min = -15
max = 15
<rules>
<rule>
condition = var(value) > 0
color = red
</rule>
<rule>
condition = var(value) < 0
color = blue
</rule>
</rules>
</plot>
</plots>
<image>
<<include etc/image.conf>>
</image>
<<include etc/colors_fonts_patterns.conf>>
<<include etc/housekeeping.conf>>Rscript make_circos_from_deseq.R
############################################################
# make_circos_from_deseq.R
#
# - Read DESeq2 results (annotated CSV)
# - Read BED annotation
# - Merge by GeneID
# - Classify genes (up / down / ns)
# - Create Circos input files:
# * genes_scatter.txt
# * density_up.txt
# * density_down.txt
# - Create annotated versions of the above
# - Export annotated tables into one Excel workbook
############################################################
###############################
# 0. Single parameter to set
###############################
# Just change this line for each comparison:
#comparison <- "Moxi_18h_vs_Untreated_18h"
# e.g.
#comparison <- "Mitomycin_18h_vs_Untreated_18h"
#comparison <- "Mitomycin_8h_vs_Untreated_8h"
#comparison <- "Moxi_8h_vs_Untreated_8h"
#comparison <- "Mitomycin_4h_vs_Untreated_4h"
comparison <- "Moxi_4h_vs_Untreated_4h"
###############################
# 0. Derived settings
###############################
# DESeq2 result file (annotated)
deseq_file <- paste0(comparison, "-all_annotated.csv")
# BED file with gene coordinates (constant for this genome)
bed_file <- "CP052959_m.bed"
# Create a filesystem-friendly directory name from comparison
safe_comp <- gsub("[^A-Za-z0-9_]+", "_", comparison)
# Output directory for Circos files (e.g. circos_Moxi_18h_vs_Untreated_18h)
out_dir <- paste0("circos_", safe_comp)
# Thresholds for significance
padj_cutoff <- 0.05
lfc_cutoff <- 1 # |log2FC| >= 1
# Bin size for density in bp (e.g. 10000 = 10 kb)
bin_size <- 10000
# Comparison label for Excel / plots (human-readable)
comparison_label <- comparison
options(scipen = 999) # turn off scientific notation
###############################
# 1. Setup & packages
###############################
if (!dir.exists(out_dir)) dir.create(out_dir, showWarnings = FALSE)
data_dir <- file.path(out_dir, "data")
if (!dir.exists(data_dir)) dir.create(data_dir, showWarnings = FALSE)
# openxlsx for Excel export
if (!requireNamespace("openxlsx", quietly = TRUE)) {
stop("Package 'openxlsx' is required. Please install it with install.packages('openxlsx').")
}
library(openxlsx)
###############################
# 2. Read data
###############################
message("Reading DESeq2 results from: ", deseq_file)
deseq <- read.csv(deseq_file, stringsAsFactors = FALSE)
# Check required columns in DESeq2 table
required_cols <- c("GeneID", "log2FoldChange", "padj")
if (!all(required_cols %in% colnames(deseq))) {
stop("DESeq2 table must contain columns: ", paste(required_cols, collapse = ", "))
}
message("Reading BED annotation from: ", bed_file)
bed_cols <- c("chr","start","end","gene_id","score",
"strand","thickStart","thickEnd",
"itemRgb","blockCount","blockSizes","blockStarts")
annot <- read.table(
bed_file,
header = FALSE,
sep = "\t",
stringsAsFactors = FALSE,
col.names = bed_cols
)
###############################
# 3. Merge DESeq2 + annotation
###############################
# Match DESeq2 GeneID (e.g. "gene-HJI06_09365") to BED gene_id
merged <- merge(
deseq,
annot[, c("chr", "start", "end", "gene_id")],
by.x = "GeneID",
by.y = "gene_id"
)
if (nrow(merged) == 0) {
stop("No overlap between DESeq2 GeneID and BED gene_id.")
}
# Midpoint of each gene
merged$mid <- round((merged$start + merged$end) / 2)
###############################
# 4. Classify genes
###############################
merged$regulation <- "ns"
merged$regulation[merged$padj < padj_cutoff & merged$log2FoldChange >= lfc_cutoff] <- "up"
merged$regulation[merged$padj < padj_cutoff & merged$log2FoldChange <= -lfc_cutoff] <- "down"
table_reg <- table(merged$regulation)
message("Regulation counts: ", paste(names(table_reg), table_reg, collapse = " | "))
###############################
# 5. Scatter files (per-gene)
###############################
scatter <- merged[merged$regulation != "ns", ]
# Circos scatter input: chr start end value
scatter_file <- file.path(data_dir, "genes_scatter.txt")
scatter_out <- scatter[, c("chr", "mid", "mid", "log2FoldChange")]
write.table(scatter_out,
scatter_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = FALSE)
message("Written Circos scatter file: ", scatter_file)
# Annotated scatter for Excel / inspection
scatter_annot <- scatter[, c(
"chr",
"mid", # start
"mid", # end
"log2FoldChange",
"GeneID",
"padj",
"regulation"
)]
colnames(scatter_annot)[1:4] <- c("chr", "start", "end", "log2FoldChange")
scatter_annot_file <- file.path(data_dir, "genes_scatter_annotated.tsv")
write.table(scatter_annot,
scatter_annot_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = TRUE)
message("Written annotated scatter file: ", scatter_annot_file)
###############################
# 6. Density function (bins)
###############################
bin_chr <- function(df_chr, bin_size, direction = c("up", "down")) {
direction <- match.arg(direction)
chr_name <- df_chr$chr[1]
max_pos <- max(df_chr$mid)
# number of bins
n_bins <- ceiling((max_pos + 1) / bin_size)
starts <- seq(0, by = bin_size, length.out = n_bins)
ends <- starts + bin_size
# init counts & gene lists
counts <- integer(n_bins)
gene_list <- vector("list", n_bins)
df_dir <- df_chr[df_chr$regulation == direction, ]
if (nrow(df_dir) > 0) {
# bin index for each gene
bin_index <- floor(df_dir$mid / bin_size) + 1
bin_index[bin_index < 1] <- 1
bin_index[bin_index > n_bins] <- n_bins
# accumulate counts and GeneIDs
for (i in seq_len(nrow(df_dir))) {
idx <- bin_index[i]
counts[idx] <- counts[idx] + 1L
gene_list[[idx]] <- c(gene_list[[idx]], df_dir$GeneID[i])
}
}
gene_ids <- vapply(
gene_list,
function(x) {
if (length(x) == 0) "" else paste(unique(x), collapse = ";")
},
character(1)
)
data.frame(
chr = chr_name,
start = as.integer(starts),
end = as.integer(ends),
value = as.integer(counts),
gene_ids = gene_ids,
stringsAsFactors = FALSE
)
}
###############################
# 7. Density up/down for all chromosomes
###############################
chr_list <- split(merged, merged$chr)
density_up_list <- lapply(chr_list, bin_chr, bin_size = bin_size, direction = "up")
density_down_list <- lapply(chr_list, bin_size = bin_size, FUN = bin_chr, direction = "down")
density_up <- do.call(rbind, density_up_list)
density_down <- do.call(rbind, density_down_list)
# Plain Circos input (no gene_ids)
density_up_file <- file.path(data_dir, "density_up.txt")
density_down_file <- file.path(data_dir, "density_down.txt")
write.table(density_up[, c("chr", "start", "end", "value")],
density_up_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = FALSE)
write.table(density_down[, c("chr", "start", "end", "value")],
density_down_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = FALSE)
message("Written Circos density files: ",
density_up_file, " and ", density_down_file)
# Annotated density files (with gene_ids)
density_up_annot_file <- file.path(data_dir, "density_up_annotated.tsv")
density_down_annot_file <- file.path(data_dir, "density_down_annotated.tsv")
write.table(density_up,
density_up_annot_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = TRUE)
write.table(density_down,
density_down_annot_file,
quote = FALSE, sep = "\t",
row.names = FALSE, col.names = TRUE)
message("Written annotated density files: ",
density_up_annot_file, " and ", density_down_annot_file)
###############################
# 8. Export annotated tables to Excel
###############################
excel_file <- file.path(
out_dir,
paste0("circos_annotations_", comparison_label, ".xlsx")
)
wb <- createWorkbook()
addWorksheet(wb, "scatter_points")
writeData(wb, "scatter_points", scatter_annot)
addWorksheet(wb, "density_up")
writeData(wb, "density_up", density_up)
addWorksheet(wb, "density_down")
writeData(wb, "density_down", density_down)
saveWorkbook(wb, excel_file, overwrite = TRUE)
message("Excel workbook written to: ", excel_file)
message("Done.")To install and prepare NCBI AMRFinderPlus in the bacto environment:
mamba activate bacto
mamba install ncbi-amrfinderplus
mamba update ncbi-amrfinderplus
mamba activate bacto
amrfinder -u/home/jhuang/mambaforge/envs/bacto/share/amrfinderplus/data/.Check available organism options for annotation:
amrfinder --list_organisms
#Available --organism options: Acinetobacter_baumannii, Burkholderia_cepacia, Burkholderia_mallei, Burkholderia_pseudomallei, Campylobacter, Citrobacter_freundii, Clostridioides_difficile, Corynebacterium_diphtheriae, Enterobacter_asburiae, Enterobacter_cloacae, Enterococcus_faecalis, Enterococcus_faecium, Escherichia, Klebsiella_oxytoca, Klebsiella_pneumoniae, Neisseria_gonorrhoeae, Neisseria_meningitidis, Pseudomonas_aeruginosa, Salmonella, Serratia_marcescens, Staphylococcus_aureus, Staphylococcus_pseudintermedius, Streptococcus_agalactiae, Streptococcus_pneumoniae, Streptococcus_pyogenes, Vibrio_cholerae, Vibrio_parahaemolyticus, Vibrio_vulnificusEscherichia, Klebsiella_pneumoniae, Enterobacter_cloacae, Pseudomonas_aeruginosa and many others.Use the following script to screen multiple genomes using AMRFinderPlus and output only β-lactam/beta-lactamase hits from a metadata table.
Input:
genome_metadata.tsv — tab-separated columns: filename_TAB_organism, with header.
filename organism
58.fasta Escherichia coli
92.fasta Klebsiella pneumoniae
125.fasta Enterobacter cloacae complex
128.fasta Enterobacter cloacae complex
130.fasta Enterobacter cloacae complex
147.fasta Citrobacter freundii
149.fasta Citrobacter freundii
160.fasta Citrobacter braakii
161.fasta Citrobacter braakii
168.fasta Providencia stuartii
184.fasta Klebsiella aerogenes
65.fasta Pseudomonas aeruginosa
201.fasta Pseudomonas aeruginosa
209.fasta Pseudomonas aeruginosa
167.fasta Serratia marcescensRun:
cd ~/DATA/Data_Patricia_AMRFinderPlus_2025/genomes
./run_amrfinder_and_summarize.sh genome_metadata.tsv
#./run_amrfinder_and_summarize.sh genome_metadata_149.tsv
#OR_DETECT_RUN: amrfinder -n 92.fasta -o amrfinder_results/92.amrfinder.tsv --plus --organism Klebsiella_pneumoniae --threads 1
python summarize_from_amrfinder_results.py amrfinder_results
# or, since that's the default:
# python summarize_from_amrfinder_results.pyProduce
AMRFinder-wide outputs
β-lactam-only outputs (if Class and Subclass are present)
Report
Please find attached the updated AMRFinderPlus summary files, now including isolate 167. For β-lactam–specific results, please see beta_lactam_all.xlsx and beta_lactam_summary.xlsx. In particular, beta_lactam_summary.xlsx contains two sheets:
Script:
run_amrfinder_and_summarize.sh
#!/usr/bin/env bash
set -euo pipefail
META_FILE="${1:-}"
if [[ -z "$META_FILE" || ! -f "$META_FILE" ]]; then
echo "Usage: $0 genome_metadata.tsv" >&2
exit 1
fi
OUTDIR="amrfinder_results"
mkdir -p "$OUTDIR"
echo ">>> Checking AMRFinder installation..."
amrfinder -V || { echo "ERROR: amrfinder not working"; exit 1; }
echo
echo ">>> Running AMRFinderPlus on all genomes listed in $META_FILE"
# --- loop over metadata file ---
# expected columns: filename
<TAB>organism
tail -n +2 "$META_FILE" | while IFS=$'\t' read -r fasta organism; do
# skip empty lines
[[ -z "$fasta" ]] && continue
if [[ ! -f "$fasta" ]]; then
echo "WARN: FASTA file '$fasta' not found, skipping."
continue
fi
isolate_id="${fasta%.fasta}"
# map free-text organism to AMRFinder --organism names (optional)
org_opt=""
case "$organism" in
"Escherichia coli") org_opt="--organism Escherichia" ;;
"Klebsiella pneumoniae") org_opt="--organism Klebsiella_pneumoniae" ;;
"Enterobacter cloacae complex") org_opt="--organism Enterobacter_cloacae" ;;
"Citrobacter freundii") org_opt="--organism Citrobacter_freundii" ;;
"Citrobacter braakii") org_opt="--organism Citrobacter_freundii" ;;
"Pseudomonas aeruginosa") org_opt="--organism Pseudomonas_aeruginosa" ;;
"Serratia marcescens") org_opt="--organism Serratia_marcescens" ;;
# others (Providencia stuartii, Klebsiella aerogenes)
# currently have no organism-specific rules in AMRFinder, so we omit --organism
*) org_opt="" ;;
esac
out_tsv="${OUTDIR}/${isolate_id}.amrfinder.tsv"
echo " - ${fasta} (${organism}) -> ${out_tsv} ${org_opt}"
amrfinder -n "$fasta" -o "$out_tsv" --plus $org_opt
done
echo ">>> AMRFinderPlus runs finished."
echo ">>> All done."
echo " - Individual reports: ${OUTDIR}/*.amrfinder.tsv"summarize_from_amrfinder_results.py
#!/usr/bin/env python3
"""
summarize_from_amrfinder_results.py
Usage:
python summarize_from_amrfinder_results.py [amrfinder_results_dir]
Default directory is "amrfinder_results" (relative to current working dir).
This script:
1) Reads all *.amrfinder.tsv in the given directory
2) Merges them into a combined table
3) Generates AMRFinder-wide summaries (amrfinder_* files)
4) Applies a β-lactam filter:
Element type == "AMR" (case-insensitive)
AND Class or Subclass contains "beta-lactam" (case-insensitive)
and generates β-lactam-only summaries (beta_lactam_* files).
It NEVER re-runs AMRFinder; it only uses existing TSV files.
"""
import sys
import os
import glob
import re
try:
import pandas as pd
except ImportError:
sys.stderr.write(
"ERROR: pandas is not installed.\n"
"Install with something like:\n"
" mamba install pandas openpyxl -c conda-forge -c bioconda\n"
)
sys.exit(1)
# ---------------------------------------------------------------------
# Helpers
# ---------------------------------------------------------------------
def read_one(path):
"""Read one *.amrfinder.tsv and add an 'isolate_id' column from the filename."""
df = pd.read_csv(path, sep="\t", dtype=str)
df.columns = [c.strip() for c in df.columns]
isolate_id = os.path.basename(path).replace(".amrfinder.tsv", "")
df["isolate_id"] = isolate_id
return df
def pick(df, *candidates):
"""Return the first existing column name among candidates (normalized names)."""
for c in candidates:
if c in df.columns:
return c
return None
# ---------------------------------------------------------------------
# AMRFinder-wide summaries (no β-lactam filter)
# ---------------------------------------------------------------------
def make_amrfinder_summaries(
df_all,
col_gene,
col_seq,
col_class,
col_subcls,
col_ident,
col_cov,
col_iso,
):
"""Summaries for ALL AMRFinder hits (no β-lactam filter)."""
if df_all.empty:
print("[amrfinder] No rows in merged table, skipping summaries.")
return
# full merged table
df_all.to_csv("amrfinder_all.tsv", sep="\t", index=False)
print(">>> Full AMRFinder table written to: amrfinder_all.tsv")
# ---- summary by isolate × gene ----
rows = []
for (iso, gene), sub in df_all.groupby([col_iso, col_gene], dropna=False):
row = {
"isolate_id": iso,
"Gene_symbol": sub[col_gene].iloc[0],
"n_hits": len(sub),
}
if col_seq is not None:
row["Sequence_name"] = sub[col_seq].iloc[0]
if col_class is not None:
row["Class"] = sub[col_class].iloc[0]
if col_subcls is not None:
row["Subclass"] = sub[col_subcls].iloc[0]
if col_ident is not None:
vals = pd.to_numeric(sub[col_ident], errors="coerce")
row["%identity_min"] = vals.min()
row["%identity_max"] = vals.max()
if col_cov is not None:
vals = pd.to_numeric(sub[col_cov], errors="coerce")
row["%coverage_min"] = vals.min()
row["%coverage_max"] = vals.max()
rows.append(row)
summary_iso_gene = pd.DataFrame(rows)
summary_iso_gene.to_csv(
"amrfinder_summary_by_isolate_gene.tsv", sep="\t", index=False
)
print(">>> Isolate × gene summary written to: amrfinder_summary_by_isolate_gene.tsv")
# ---- summary by gene ----
def join(vals):
uniq = sorted(set(vals.dropna().astype(str)))
return ",".join(uniq)
rows = []
for gene, sub in df_all.groupby(col_gene, dropna=False):
row = {
"Gene_symbol": sub[col_gene].iloc[0],
"n_isolates": sub[col_iso].nunique(),
"isolates": ",".join(sorted(set(sub[col_iso].dropna().astype(str)))),
"n_hits": len(sub),
}
if col_seq is not None:
row["Sequence_name"] = join(sub[col_seq])
if col_class is not None:
row["Class"] = join(sub[col_class])
if col_subcls is not None:
row["Subclass"] = join(sub[col_subcls])
rows.append(row)
summary_gene = pd.DataFrame(rows)
summary_gene = summary_gene.sort_values("n_isolates", ascending=False)
summary_gene.to_csv("amrfinder_summary_by_gene.tsv", sep="\t", index=False)
print(">>> Gene-level summary written to: amrfinder_summary_by_gene.tsv")
# ---- summary by class/subclass ----
summary_class = None
if col_class is not None:
group_cols = [col_class]
if col_subcls is not None:
group_cols.append(col_subcls)
summary_class = (
df_all.groupby(group_cols, dropna=False)
.agg(
n_isolates=(col_iso, "nunique"),
n_hits=(col_iso, "size"),
)
.reset_index()
)
summary_class.to_csv("amrfinder_summary_by_class.tsv", sep="\t", index=False)
print(">>> Class-level summary written to: amrfinder_summary_by_class.tsv")
else:
print(">>> No 'class' column found; amrfinder_summary_by_class.tsv not created.")
# ---- Excel workbook ----
try:
with pd.ExcelWriter("amrfinder_summary.xlsx") as xw:
df_all.to_excel(xw, sheet_name="amrfinder_all", index=False)
summary_iso_gene.to_excel(xw, sheet_name="by_isolate_gene", index=False)
summary_gene.to_excel(xw, sheet_name="by_gene", index=False)
if summary_class is not None:
summary_class.to_excel(xw, sheet_name="by_class", index=False)
print(">>> Excel workbook written: amrfinder_summary.xlsx")
except Exception as e:
print("WARNING: could not write amrfinder_summary.xlsx:", e)
# ---------------------------------------------------------------------
# β-lactam summaries
# ---------------------------------------------------------------------
def make_beta_lactam_summaries(
df_beta,
col_gene,
col_seq,
col_subcls,
col_ident,
col_cov,
col_iso,
):
"""Summaries for β-lactam subset (after mask)."""
if df_beta.empty:
print("[beta_lactam] No β-lactam hits in subset, skipping.")
return
# full β-lactam table
beta_all_tsv = "beta_lactam_all.tsv"
df_beta.to_csv(beta_all_tsv, sep="\t", index=False)
print(">>> β-lactam / β-lactamase hits written to: %s" % beta_all_tsv)
# -------- summary by gene (with list of isolates) --------
group_cols = [col_gene]
if col_seq is not None:
group_cols.append(col_seq)
if col_subcls is not None:
group_cols.append(col_subcls)
def join_isolates(vals):
uniq = sorted(set(vals.dropna().astype(str)))
return ",".join(uniq)
summary_gene = (
df_beta.groupby(group_cols, dropna=False)
.agg(
n_isolates=(col_iso, "nunique"),
isolates=(col_iso, join_isolates),
n_hits=(col_iso, "size"),
)
.reset_index()
)
rename_map = {}
if col_gene is not None:
rename_map[col_gene] = "Gene_symbol"
if col_seq is not None:
rename_map[col_seq] = "Sequence_name"
if col_subcls is not None:
rename_map[col_subcls] = "Subclass"
summary_gene.rename(columns=rename_map, inplace=True)
sum_gene_tsv = "beta_lactam_summary_by_gene.tsv"
summary_gene.to_csv(sum_gene_tsv, sep="\t", index=False)
print(">>> Gene-level β-lactam summary written to: %s" % sum_gene_tsv)
print(" (includes 'isolates' = comma-separated isolate_ids)")
# -------- summary by isolate & gene (with annotation) --------
rows = []
for (iso, gene), sub in df_beta.groupby([col_iso, col_gene], dropna=False):
row = {
"isolate_id": iso,
"Gene_symbol": sub[col_gene].iloc[0],
"n_hits": len(sub),
}
if col_seq is not None:
row["Sequence_name"] = sub[col_seq].iloc[0]
if col_subcls is not None:
row["Subclass"] = sub[col_subcls].iloc[0]
if col_ident is not None:
vals = pd.to_numeric(sub[col_ident], errors="coerce")
row["%identity_min"] = vals.min()
row["%identity_max"] = vals.max()
if col_cov is not None:
vals = pd.to_numeric(sub[col_cov], errors="coerce")
row["%coverage_min"] = vals.min()
row["%coverage_max"] = vals.max()
rows.append(row)
summary_iso_gene = pd.DataFrame(rows)
sum_iso_gene_tsv = "beta_lactam_summary_by_isolate_gene.tsv"
summary_iso_gene.to_csv(sum_iso_gene_tsv, sep="\t", index=False)
print(">>> Isolate × gene β-lactam summary written to: %s" % sum_iso_gene_tsv)
print(" (includes 'Gene_symbol' and 'Sequence_name' annotation columns)")
# -------- optional Excel exports --------
try:
with pd.ExcelWriter("beta_lactam_all.xlsx") as xw:
df_beta.to_excel(xw, sheet_name="beta_lactam_all", index=False)
with pd.ExcelWriter("beta_lactam_summary.xlsx") as xw:
summary_gene.to_excel(xw, sheet_name="by_gene", index=False)
summary_iso_gene.to_excel(xw, sheet_name="by_isolate_gene", index=False)
print(">>> Excel workbooks written: beta_lactam_all.xlsx, beta_lactam_summary.xlsx")
except Exception as e:
print("WARNING: could not write β-lactam Excel files:", e)
# ---------------------------------------------------------------------
# Main
# ---------------------------------------------------------------------
def main():
outdir = sys.argv[1] if len(sys.argv) > 1 else "amrfinder_results"
if not os.path.isdir(outdir):
sys.stderr.write("ERROR: directory '%s' not found.\n" % outdir)
sys.exit(1)
files = sorted(glob.glob(os.path.join(outdir, "*.amrfinder.tsv")))
if not files:
sys.stderr.write("ERROR: no *.amrfinder.tsv files found in '%s'.\n" % outdir)
sys.exit(1)
print(">>> Found %d AMRFinder TSV files in: %s" % (len(files), outdir))
for f in files:
print(" -", os.path.basename(f))
dfs = [read_one(f) for f in files]
df = pd.concat(dfs, ignore_index=True)
# normalize column names for internal use
norm_cols = {c: c.strip().lower().replace(" ", "_") for c in df.columns}
df.rename(columns=norm_cols, inplace=True)
# locate columns (handles your Element type / subtype + older formats)
col_gene = pick(df, "gene_symbol", "genesymbol")
col_seq = pick(df, "sequence_name", "sequencename")
col_elemtype = pick(df, "element_type")
col_elemsub = pick(df, "element_subtype")
col_class = pick(df, "class")
col_subcls = pick(df, "subclass")
col_ident = pick(df, "%identity_to_reference_sequence", "identity")
col_cov = pick(df, "%coverage_of_reference_sequence", "coverage_of_reference_sequence")
col_iso = "isolate_id"
print("\nDetected columns:")
for label, col in [
("gene", col_gene),
("sequence", col_seq),
("element_type", col_elemtype),
("element_subtype", col_elemsub),
("class", col_class),
("subclass", col_subcls),
("%identity", col_ident),
("%coverage", col_cov),
("isolate_id", col_iso),
]:
print(" %-14s: %s" % (label, col))
if col_gene is None:
sys.stderr.write(
"ERROR: could not find a gene symbol column "
"(expected something like 'Gene symbol' in the original AMRFinder output).\n"
)
sys.exit(1)
print("\n=== Generating AMRFinder-wide summaries (all hits) ===")
make_amrfinder_summaries(
df_all=df,
col_gene=col_gene,
col_seq=col_seq,
col_class=col_class,
col_subcls=col_subcls,
col_ident=col_ident,
col_cov=col_cov,
col_iso=col_iso,
)
# -----------------------------------------------------------------
# β-lactam subset
#
# New logic for your current data:
# Element type == "AMR"
# AND Class or Subclass contains "beta-lactam"
#
# Falls back to just Class/Subclass if Element type not present.
# -----------------------------------------------------------------
if (col_elemtype is not None) or (col_class is not None or col_subcls is not None):
# element type AMR (if column exists, otherwise all True)
if col_elemtype is not None:
mask_amr = df[col_elemtype].str.contains("AMR", case=False, na=False)
else:
mask_amr = pd.Series(True, index=df.index)
# beta-lactam pattern (handles BETA-LACTAM, beta lactam, etc.)
beta_pattern = re.compile(r"beta[- ]?lactam", re.IGNORECASE)
mask_beta = pd.Series(False, index=df.index)
if col_class is not None:
mask_beta |= df[col_class].fillna("").str.contains(beta_pattern)
if col_subcls is not None:
mask_beta |= df[col_subcls].fillna("").str.contains(beta_pattern)
mask = mask_amr & mask_beta
df_beta = df.loc[mask].copy()
if df_beta.empty:
print(
"\nWARNING: No β-lactam hits found "
"(Element type == 'AMR' AND Class/Subclass contains 'beta-lactam')."
)
else:
print(
"\n=== β-lactam subset ===\n"
" kept %d of %d rows where Element type is 'AMR' and "
"Class/Subclass contains 'beta-lactam'\n"
% (len(df_beta), len(df))
)
make_beta_lactam_summaries(
df_beta=df_beta,
col_gene=col_gene,
col_seq=col_seq,
col_subcls=col_subcls,
col_ident=col_ident,
col_cov=col_cov,
col_iso=col_iso,
)
else:
print(
"\nWARNING: Cannot apply β-lactam filter because Element type and/or "
"class/subclass columns were not found. Only amrfinder_* "
"outputs were generated."
)
if __name__ == "__main__":
main()Title: Automated Kymograph Track Filtering & Lake File Generation (kymograph轨迹自动过滤与Lake文件生成流程)
(用1_filter_track.py进行轨迹过滤) 运行命令:
python 1_filter_track.py 核心思路:对每个原始*_blue.csv轨迹文件,根据位置和寿命(lifetime)进行过滤,将保留的轨迹和被剔除的轨迹分别存放于两个目录:
(整理过滤结果CSV,修正文件名命名错误) 创建文件夹:
mkdir filtered_blue_position filtered_blue_position_1s filtered_blue_position_5s filtered_blue_lifetime_5s_only移动对应过滤文件:
绑定位置2.2–3.8 µm
mv filtered/*_blue_position.csv filtered_blue_position绑定位置且寿命≥1s
mv filtered/*_blue_position_1s.csv filtered_blue_position_1s绑定位置且寿命≥5s
mv filtered/*_blue_position_5s.csv filtered_blue_position_5s寿命≥5s不限制位置
mv filtered/*_blue_lifetime_5s_only.csv filtered_blue_lifetime_5s_only每个目录保留74个CSV文件(包含真实轨迹和header-only占位符)。 修正p940命名bug(文件名中p940与lake文件中940不匹配),统一去除多余的p:
find filtered_blue_position -type f -name 'p*_p[0-9][0-9][0-9]_*.csv' -exec rename 's/_p([0-9]{3})/_$1/' {} +
(同理在其它三个目录执行相同命令)保证轨迹CSV名与lake文件中kymograph名称一一对应。
(把过滤后轨迹写回lake文件) 运行命令更新lake文件(每组过滤条件对应一组输出目录):
python 2_update_lakes.py --merged_lake_folder lakes_raw --filtered_folder filtered_blue_position --output_folder lakes_blue_position_2.2-3.8 | tee blue_position_2.2-3.8.LOG
python 2_update_lakes.py --merged_lake_folder lakes_raw --filtered_folder filtered_blue_position_1s --output_folder lakes_blue_position_2.2-3.8_length_min_1s | tee blue_position_2.2-3.8_length_min_1s.LOG
python 2_update_lakes.py --merged_lake_folder lakes_raw --filtered_folder filtered_blue_position_5s --output_folder lakes_blue_position_2.2-3.8_length_min_5s | tee blue_position_2.2-3.8_length_min_5s.LOG
python 2_update_lakes.py --merged_lake_folder lakes_raw --filtered_folder filtered_blue_lifetime_5s_only --output_folder lakes_blue_length_min_5s | tee blue_length_min_5s.LOG处理逻辑:
最终实现每个replicate拥有多组更新的lake文件,各文件中kymographs、experiments[…].dataset、file_viewer的H5链接一致对应,确保完整性和可追踪性。
此流程自动化实现kymograph轨迹质量控制与lake文件二次生成,支持多样过滤条件,保证下游数据分析准确可靠。
FAU“身体活动与健康”硕士项目:申请指南与入学要求
“身体活动与健康”硕士项目(MA Programme Physical Activity and Health)只能在冬季学期开始(课程于2024年10月开课),针对2025/26冬季学期的申请将于2025年2月15日开始。申请截止日期为2025年5月31日。我们建议非欧盟公民最迟于2025年3月31日前提交申请,以便有充足时间办理签证手续。 所有所需申请材料必须通过线上系统[Campo(https://www.campo.fau.de/qisserver/pages/cs/sys/portal/hisinoneStartPage.faces)提交。(请不要邮寄任何申请材料到FAU,所有文件须通过Campo平台在线上传。)
在申请“身体活动与健康”硕士项目时,需要提交以下文件:
动机信是你申请材料的重要部分。请说明为什么想加入本项目,以及你未来的职业规划。此外,应提及你先前在身体活动、物理治疗或公共卫生等主题领域的经验。篇幅应为1至2页。
简历应简要说明你的中学和大学学习经历,列出最近就读的所有学校或大学。包括与你申请项目相关的实习、兼职或全职工作经历。同时应注明出生日期与地点、国籍及现居地点。可以使用Europass简历模板(下载模板及说明,或访问Europass主页)。
需提交中学和大学期间所有学历及成绩单的经认证复印件。这些文件仅通过电子邮件提交(不接受邮寄或传真)。所有复印件必须经过正式认证。认证文件须:
项目对非运动科学、物理治疗、康复科学、健康教育等背景的学生开放。请列出与你本项目相关的所有课程,例如运动科学、体育教育、物理治疗、康复科学、老年学、公共卫生、流行病学、研究方法或统计学等。
Listing of courses/classes with high relevance to our programme (for applicants with degrees in Physical Education, Psychology, Sociology, Political Science, Anthropology, or Medicine only) The programme is open to students who do not have degrees in Sport Science, Kinesiology /Exercise Science, Physiotherapy, Rehabilitation Science, Health Education, Health Science/Public Health.
Such other degrees can be e.g. Physical Education, Psychology, Sociology, Political Science, Anthropology, or Medicine). This list should provide us with a brief summary of all classes or coursework that you have attended and that are relevant to the subject areas of physical activity and/or (public) health. Potential examples include courses/classes covering the topics of sport science, physical education, physical therapy, rehabilitation science, kinesiology, gerontology, public health, epidemiology, research methods, or statistics.
具有上述专业背景的学生,需提供至少一年全职相关工作经验(运动科学、康复科学、治疗科学或公共卫生领域)证明,可由相关机构出具证明信。
Documentation of 1 year work experience in the fields of Sport Science/ Rehabilitation Science or Therapeutic Science/ Public Health (for applicants with degrees in Physical Education, Psychology, Sociology, Political Science, Anthropology, or Medicine only) The programme is open to students who do not have degrees in Sport Science, Kinesiology /Exercise Science, Physiotherapy, Rehabilitation Science, Therapeutic Science, Health Education, or Health Science/Public Health.
Such other degrees can be e.g. Physical Education, Psychology, Sociology, Political Science, Anthropology, or Medicine. Students with such degrees need to document at least 1 year of work experience (full-time) in the fields of Sport Science, Reahbilitation Science or Therapeutic Science, or Public Health in order to be eligible to apply to the programme. The documentation can be an attached letter from the institution/company.
本项目以英语授课,需要具备足够的听、说、读、写能力。若母语非英语且本科/硕士授课语言非英语,需提供语言证书证明达到我们要求的水平。最低要求为CEFR体系的B2级。详情见入学要求。
根据州级规定,所有母语非德语学生须在入学一年内至少达到A1级德语水平。若已有德语水平,请在申请材料中提供证明;若尚未具备,也可申请。大学提供免费德语课程,可在第一学年内学习。所有课程与考试均以英语进行。
所有申请材料须通过Campo平台提交。(请不要邮寄任何文件至FAU,所有文件仅通过Campo上传。)
DSS部门两位教师将依据以下标准评审申请:
如有关于硕士项目内容或申请流程的疑问,请联系项目顾问Karim Abu-Omar。 若你已通过Campo提交申请,请在联系时务必提供申请编号(application-ID),并在需要通过邮件发送的文件名称中注明该编号。]
具有以下学科之一的高等教育第一阶段学位(例如学士学位,或德国体系中的“Diplom”或“Staatsexamen”):
在特殊情况下,若申请人完成了以下相关领域的类似学位,也可被录取,例如体育教育、心理学、社会学、政治学、人类学或医学。申请人需提供证明,证明其已在运动科学/康复科学/治疗科学/公共卫生等领域修读了至少20个ECTS学分的课程,或在这些领域拥有至少1年的全职工作经验。
最低成绩要求:
目前仍在读本科的学生,在修完至少140个ECTS学分后即可申请。 正式录取前,必须提交最终成绩单及学士学位证书;被录取的申请者若尚未提交最终文件,其录取为有条件录取。
本硕士项目的所有课程均以英语授课。 所有母语非英语的申请者,须提供至少达到CEFR欧洲语言能力等级框架B2级的英语语言能力证明。
若你持有其他类型的语言证书,可参考以下证书等级对照表,以了解与CEFR B2等级约等的分数范围: 语言证书对照表 请注意:该对照表仅用于参考,不具法律效力。若提交的证书或成绩未标明CEFR等级,将由大学逐一评估是否符合要求。 未能提供CEFR B2水平英语证明的申请人,可能需要在入学前于大学语言中心参加英语水平测试。
入学时无须提供德语能力证明,但学生须在赴FAU就读的第一学年内学习德语,至少达到A1级。 建议申请者具备基本德语能力,特别是第二学年以项目研究为主的课程阶段。 大学语言中心为所有语言水平的学生提供免费的德语课程。
本硕士项目不收取学费。
This content is password-protected. To view it, please enter the password below.
Top 32 list of microbiology journals with their Impact Factors from 2024, including publisher and other relevant information based on the latest available data from the source:
| Rank | Journal Name | Impact Factor 2024 | Publisher |
|---|---|---|---|
| 1 | Nature Reviews Microbiology | ~103.3 | Springer Nature |
| 2 | Nature Microbiology | ~19.4 | Springer Nature |
| 3 | Clinical Microbiology Reviews | ~19.3 | American Society for Microbiology (ASM) |
| 4 | Cell Host \& Microbe | ~19.2 | Cell Press |
| 5 | Annual Review of Microbiology | ~12.5 | Annual Reviews |
| 6 | Trends in Microbiology | ~11.0 | Cell Press |
| 7 | Gut Microbes | ~12.0 | Taylor \& Francis |
| 8 | Microbiome | ~11.1 | Springer Nature |
| 9 | Clinical Infectious Diseases | ~9.1 | Oxford University Press |
| 10 | Journal of Clinical Microbiology* | ~6.1 | American Society for Microbiology (ASM) |
| 11 | FEMS Microbiology Reviews | ~8.9 | Oxford University Press |
| 12 | The ISME Journal | ~9.5 | Springer Nature |
| 13 | Environmental Microbiology | ~8.2 | Wiley |
| 14 | Microbes and Infection | ~7.5 | Elsevier |
| 15 | Journal of Medical Microbiology | ~4.4 | Microbiology Society |
| 16 | Frontiers in Microbiology | ~6.4 | Frontiers Media |
| 17 | MicrobiologyOpen | ~3.6 | Wiley |
| 18 | Microbial Ecology | ~4.9 | Springer Nature |
| 19 | Journal of Bacteriology | ~4.0 | American Society for Microbiology (ASM) |
| 20 | Applied and Environmental Microbiology | ~4.5 | American Society for Microbiology (ASM) |
| 21 | Pathogens and Disease | ~3.3 | Oxford University Press |
| 22 | Microbial Biotechnology | ~7.3 | Wiley |
| 23 | Antonie van Leeuwenhoek | ~3.8 | Springer Nature |
| 24 | Journal of Antimicrobial Chemotherapy | ~5.2 | Oxford University Press |
| 25 | Virulence | ~5.4 | Taylor \& Francis |
| 26 | mBio | ~6.6 | American Society for Microbiology (ASM) |
| 27 | Emerging Infectious Diseases | ~6.3 | CDC |
| 28 | Microbial Cell Factories | ~6.0 | Springer Nature |
| 29 | Microbial Pathogenesis | ~4.4 | Elsevier |
| 30 | Journal of Virology | ~5.8 | American Society for Microbiology (ASM) |
| 31 | Microbiology Spectrum | ~4.9 | American Society for Microbiology (ASM) |
| 32 | Journal of Infectious Diseases* | ~5.9 | Oxford University Press |