
In the current results, I extract the main effect. I also compared the condition deltasbp_MH_18h to WT_MH_18h, if you are interested in specific comparison between conditions, please let me know, I can perform differentially expressed analysis and draw corresponding volcano plots for them.
-
Targets
> Which genes are differentially expressed between the conditions for each time point. > Also, from our pulldown experiment, we identified several potential > target genes, and I’d be particularly interested to see if there are > expression changes for those in the RNA-seq data. I’ll include the > list of targets below once it’s ready. 简要结论:莫西沙星(Moxifloxacin)= 抗生素;丝裂霉素C(Mitomycin C)= 临床上不作为抗感染用抗生素。 莫西沙星(Moxifloxacin):第四代氟喹诺酮类抗生素,用于治疗细菌感染(如呼吸道、皮肤等)。作用机制是抑制DNA旋转酶和拓扑异构酶IV,阻断细菌DNA复制。 丝裂霉素C(Mitomycin C):本质上是来源于链霉菌的一类“抗肿瘤抗生素”,通过烷基化DNA 造成交联破坏,因此主要用于肿瘤化疗,以及少数局部应用(眼科/耳鼻喉科术中抑制瘢痕增生等)。尽管名字里有“抗生素”,也确有抗菌活性,但全身毒性过大,不用于治疗感染。 > Additionally, I have a specific question regarding the toxin–antitoxin > system I’m studying. The toxin and antitoxin genes are: > > Toxin: > ttatttacaatgcctcttgatccatgtctcaattccctcaagagtaagatttttgtcgtttactactcttaaagtaaactgaaccgcttcatcttgagtgcattcaaaattaatactatttaacttcaaaaatattaccatagatgtaaaagctgttcttttattcgcattatggaatgcgtgcttttgagctatatttctatatataaaagctgcttttctctcgattgtttcatatagttcaactccaccgaatgattgtttaactccttcaatagtagcattaagaacttctggaactttaacaccaacttgttcttttggtgagaaatcttgtattgcttttacattaatggcaatcacttgtttttcagttaaatatttagtgctttgcat > > Antitoxin: > ttataagtcaaccatcctttttaaagcttggttatactcagtgaatgtttcatccaacaatttaaaaaactcctcgtcctctcttacctccttttcgatggttactttattatcttttacattaaatttaagattatcaccatttgatattccgagtgctgcgatcacttctgtcggtacagaaacaactgaactattaccagcttttcttagttttcttgtagtaatcat > > I’m wondering whether you can check if these two genes might share the > same promoter and whether any RNA-seq signal supports their > co-expression. -
Download and prepare raw data
# ---- Dataset_1 ---- aws configure > Aws_access_key_id:AKIAYWZZRVKWTQDI4CHT > Aws_secret_access_key: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 > > aws s3 cp s3://staefgap-598731762349/ ./ --recursive #S3 Bucket # ---- Dataset_2 ---- aws configure > Aws_access_key_id:AKIAYWZZRVKWXL5FYUBC > Aws_secret_access_key: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 > > aws s3 cp s3://stavoupp-598731762349/ ./ --recursive #S3 Bucket mkdir raw_data; cd raw_data ln -s ../F25A430001462_STAvoupP/1a_untreated_4h/1a_untreated_4h_1.fq.gz Untreated_4h_1a_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1a_untreated_4h/1a_untreated_4h_2.fq.gz Untreated_4h_1a_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1b_untreated_4h/1b_untreated_4h_1.fq.gz Untreated_4h_1b_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1b_untreated_4h/1b_untreated_4h_2.fq.gz Untreated_4h_1b_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1c_untreated_4h/1c_untreated_4h_1.fq.gz Untreated_4h_1c_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1c_untreated_4h/1c_untreated_4h_2.fq.gz Untreated_4h_1c_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1d_untreated_8h/1d_untreated_8h_1.fq.gz Untreated_8h_1d_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1d_untreated_8h/1d_untreated_8h_2.fq.gz Untreated_8h_1d_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1e_untreated_8h/1e_untreated_8h_1.fq.gz Untreated_8h_1e_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1e_untreated_8h/1e_untreated_8h_2.fq.gz Untreated_8h_1e_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1f_untreated_8h/1f_untreated_8h_1.fq.gz Untreated_8h_1f_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1f_untreated_8h/1f_untreated_8h_2.fq.gz Untreated_8h_1f_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1g_untreated18h/1g_untreated18h_1.fq.gz Untreated_18h_1g_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1g_untreated18h/1g_untreated18h_2.fq.gz Untreated_18h_1g_R2.fastq.gz ln -s ../F25A430001462_STAefgaP/1h_untreated18h/1h_untreated18h_1.fq.gz Untreated_18h_1h_R1.fastq.gz ln -s ../F25A430001462_STAefgaP/1h_untreated18h/1h_untreated18h_2.fq.gz Untreated_18h_1h_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/1i_untreated18h/1i_untreated18h_1.fq.gz Untreated_18h_1i_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/1i_untreated18h/1i_untreated18h_2.fq.gz Untreated_18h_1i_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2a_Mitomycin_4h/2a_Mitomycin_4h_1.fq.gz Mitomycin_4h_2a_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2a_Mitomycin_4h/2a_Mitomycin_4h_2.fq.gz Mitomycin_4h_2a_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2b_Mitomycin_4h/2b_Mitomycin_4h_1.fq.gz Mitomycin_4h_2b_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2b_Mitomycin_4h/2b_Mitomycin_4h_2.fq.gz Mitomycin_4h_2b_R2.fastq.gz ln -s ../F25A430001462_STAefgaP/2c_Mitomycin_4h/2c_Mitomycin_4h_1.fq.gz Mitomycin_4h_2c_R1.fastq.gz ln -s ../F25A430001462_STAefgaP/2c_Mitomycin_4h/2c_Mitomycin_4h_2.fq.gz Mitomycin_4h_2c_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2d_Mitomycin_8h/2d_Mitomycin_8h_1.fq.gz Mitomycin_8h_2d_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2d_Mitomycin_8h/2d_Mitomycin_8h_2.fq.gz Mitomycin_8h_2d_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2e_Mitomycin_8h/2e_Mitomycin_8h_1.fq.gz Mitomycin_8h_2e_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2e_Mitomycin_8h/2e_Mitomycin_8h_2.fq.gz Mitomycin_8h_2e_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2f_Mitomycin_8h/2f_Mitomycin_8h_1.fq.gz Mitomycin_8h_2f_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2f_Mitomycin_8h/2f_Mitomycin_8h_2.fq.gz Mitomycin_8h_2f_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2g_Mitomycin18h/2g_Mitomycin18h_1.fq.gz Mitomycin_18h_2g_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2g_Mitomycin18h/2g_Mitomycin18h_2.fq.gz Mitomycin_18h_2g_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2h_Mitomycin18h/2h_Mitomycin18h_1.fq.gz Mitomycin_18h_2h_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2h_Mitomycin18h/2h_Mitomycin18h_2.fq.gz Mitomycin_18h_2h_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/2i_Mitomycin18h/2i_Mitomycin18h_1.fq.gz Mitomycin_18h_2i_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/2i_Mitomycin18h/2i_Mitomycin18h_2.fq.gz Mitomycin_18h_2i_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3a_Moxi_4h/3a_Moxi_4h_1.fq.gz Moxi_4h_3a_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3a_Moxi_4h/3a_Moxi_4h_2.fq.gz Moxi_4h_3a_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3b_Moxi_4h/3b_Moxi_4h_1.fq.gz Moxi_4h_3b_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3b_Moxi_4h/3b_Moxi_4h_2.fq.gz Moxi_4h_3b_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3c_Moxi_4h/3c_Moxi_4h_1.fq.gz Moxi_4h_3c_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3c_Moxi_4h/3c_Moxi_4h_2.fq.gz Moxi_4h_3c_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3d_Moxi_8h/3d_Moxi_8h_1.fq.gz Moxi_8h_3d_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3d_Moxi_8h/3d_Moxi_8h_2.fq.gz Moxi_8h_3d_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3e_Moxi_8h/3e_Moxi_8h_1.fq.gz Moxi_8h_3e_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3e_Moxi_8h/3e_Moxi_8h_2.fq.gz Moxi_8h_3e_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3f_Moxi_8h/3f_Moxi_8h_1.fq.gz Moxi_8h_3f_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3f_Moxi_8h/3f_Moxi_8h_2.fq.gz Moxi_8h_3f_R2.fastq.gz ln -s ../F25A430001462_STAefgaP/3g_Moxi_18h/3g_Moxi_18h_1.fq.gz Moxi_18h_3g_R1.fastq.gz ln -s ../F25A430001462_STAefgaP/3g_Moxi_18h/3g_Moxi_18h_2.fq.gz Moxi_18h_3g_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3h_Moxi_18h/3h_Moxi_18h_1.fq.gz Moxi_18h_3h_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3h_Moxi_18h/3h_Moxi_18h_2.fq.gz Moxi_18h_3h_R2.fastq.gz ln -s ../F25A430001462_STAvoupP/3i_Moxi_18h/3i_Moxi_18h_1.fq.gz Moxi_18h_3i_R1.fastq.gz ln -s ../F25A430001462_STAvoupP/3i_Moxi_18h/3i_Moxi_18h_2.fq.gz Moxi_18h_3i_R2.fastq.gz -
Preparing the directory trimmed
mkdir trimmed trimmed_unpaired; for sample_id in Untreated_4h_1a Untreated_4h_1a Untreated_4h_1b Untreated_4h_1b Untreated_4h_1c Untreated_4h_1c Untreated_8h_1d Untreated_8h_1d Untreated_8h_1e Untreated_8h_1e Untreated_8h_1f Untreated_8h_1f Untreated_18h_1g Untreated_18h_1g Untreated_18h_1h Untreated_18h_1h Untreated_18h_1i Untreated_18h_1i Mitomycin_4h_2a Mitomycin_4h_2a Mitomycin_4h_2b Mitomycin_4h_2b Mitomycin_4h_2c Mitomycin_4h_2c Mitomycin_8h_2d Mitomycin_8h_2d Mitomycin_8h_2e Mitomycin_8h_2e Mitomycin_8h_2f Mitomycin_8h_2f Mitomycin_18h_2g Mitomycin_18h_2g Mitomycin_18h_2h Mitomycin_18h_2h Mitomycin_18h_2i Mitomycin_18h_2i Moxi_4h_3a Moxi_4h_3a Moxi_4h_3b Moxi_4h_3b Moxi_4h_3c Moxi_4h_3c Moxi_8h_3d Moxi_8h_3d Moxi_8h_3e Moxi_8h_3e Moxi_8h_3f Moxi_8h_3f Moxi_18h_3g Moxi_18h_3g Moxi_18h_3h Moxi_18h_3h Moxi_18h_3i Moxi_18h_3i; do java -jar /home/jhuang/Tools/Trimmomatic-0.36/trimmomatic-0.36.jar PE -threads 100 raw_data/${sample_id}_R1.fastq.gz raw_data/${sample_id}_R2.fastq.gz trimmed/${sample_id}_R1.fastq.gz trimmed_unpaired/${sample_id}_R1.fastq.gz trimmed/${sample_id}_R2.fastq.gz trimmed_unpaired/${sample_id}_R2.fastq.gz ILLUMINACLIP:/home/jhuang/Tools/Trimmomatic-0.36/adapters/TruSeq3-PE-2.fa:2:30:10:8:TRUE LEADING:3 TRAILING:3 SLIDINGWINDOW:4:15 MINLEN:36 AVGQUAL:20; done 2> trimmomatic_pe.log; done mv trimmed/*.fastq.gz . -
Preparing samplesheet.csv
sample,fastq_1,fastq_2,strandedness Untreated_4h_1a,Untreated_4h_1a_R1.fastq.gz,Untreated_4h_1a_R2.fastq.gz,auto Untreated_4h_1a,Untreated_4h_1a_R1.fastq.gz,Untreated_4h_1a_R2.fastq.gz,auto ... -
nextflow run
#See an example: http://xgenes.com/article/article-content/157/prepare-virus-gtf-for-nextflow-run/ #docker pull nfcore/rnaseq ln -s /home/jhuang/Tools/nf-core-rnaseq-3.12.0/ rnaseq # -- DEBUG_1 (CDS --> exon in CP052959.gff) -- grep -P "\texon\t" CP052959.gff | sort | wc -l #=81 grep -P "cmsearch\texon\t" CP052959.gff | wc -l #=10 signal recognition particle sRNA small typ, transfer-messenger RNA, 5S ribosomal RNA grep -P "Genbank\texon\t" CP052959.gff | wc -l #=10 16S and 23S ribosomal RNA grep -P "tRNAscan-SE\texon\t" CP052959.gff | wc -l #61 tRNA grep -P "\tCDS\t" CP052959.gff | wc -l #2581 sed 's/\tCDS\t/\texon\t/g' CP052959.gff > CP052959_m.gff grep -P "\texon\t" CP052959_m.gff | sort | wc -l #2662 (81 more comparing with 'CDS') # -- NOTE that combination of 'CP052959_m.gff' and 'exon' in the command will result in ERROR, using 'transcript' instead in the command line! --gff "/home/jhuang/DATA/Data_Tam_RNAseq_2024/CP052959_m.gff" --featurecounts_feature_type 'transcript' # ---- SUCCESSFUL with directly downloaded gff3 and fasta from NCBI using docker after replacing 'CDS' with 'exon' ---- (host_env) /usr/local/bin/nextflow run rnaseq/main.nf --input samplesheet.csv --outdir results --fasta "/home/jhuang/DATA/Data_JuliaFuchs_RNAseq/CP052959.fasta" --gff "/home/jhuang/DATA/Data_JuliaFuchs_RNAseq/CP052959_m.gff" -profile docker -resume --max_cpus 100 --max_memory 512.GB --max_time 2400.h --save_align_intermeds --save_unaligned --save_reference --aligner 'star_salmon' --gtf_group_features 'gene_id' --gtf_extra_attributes 'gene_name' --featurecounts_group_type 'gene_biotype' --featurecounts_feature_type 'transcript' # -- DEBUG_3: make sure the header of fasta is the same to the *_m.gff file, both are "CP052959.1" -
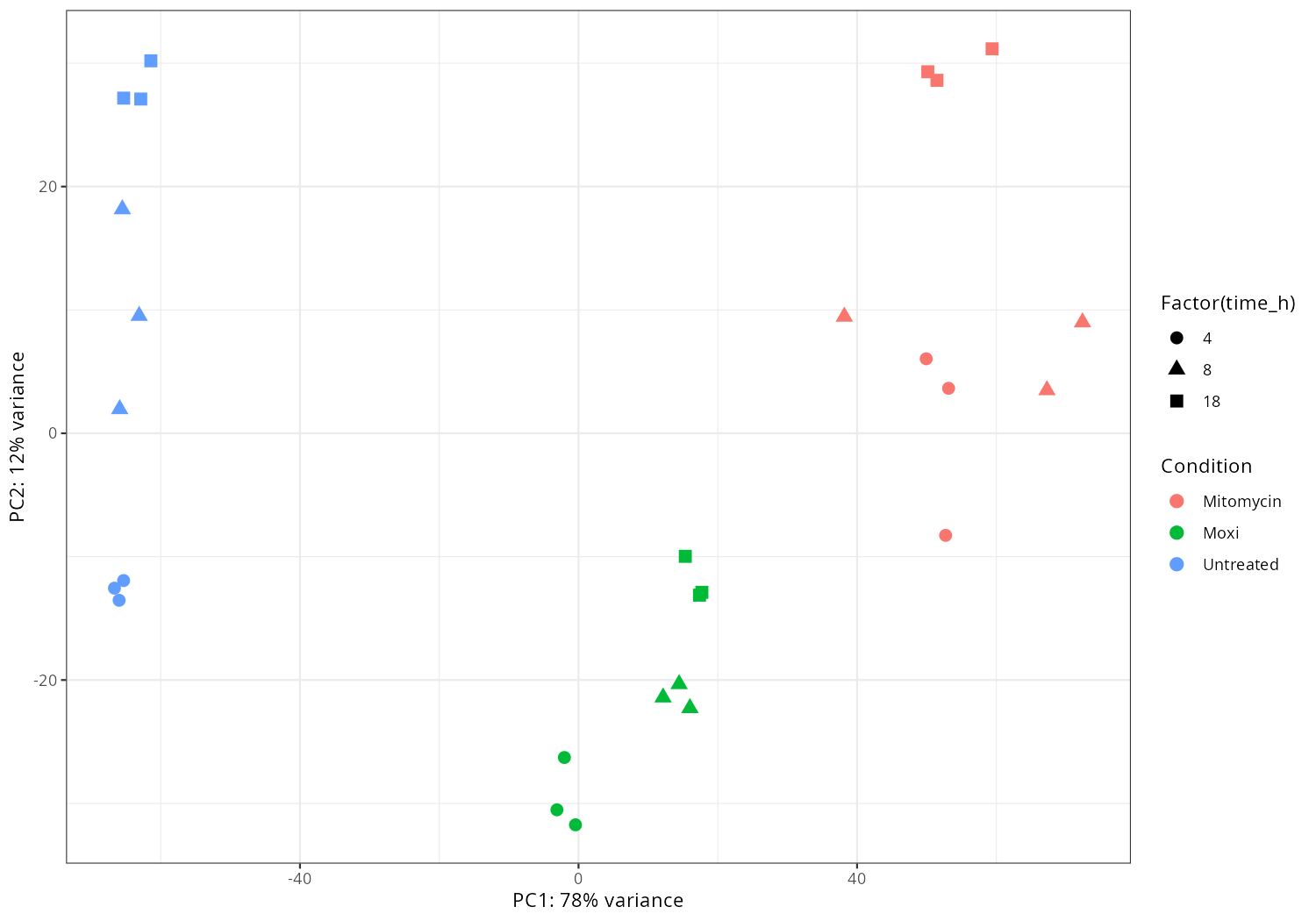
Generate advanced PCA-plot
cp ./results/star_salmon/gene_raw_counts.csv counts.tsv #keep only gene_id cut -f1 -d',' counts.tsv > f1 cut -f3- -d',' counts.tsv > f3_ paste -d',' f1 f3_ > counts_fixed.tsv #IMPORTANT_EDIT: delete all """, "gene-", replace ',' to '\t' in counts_fixed.tsv. #IMPORTANT_ENV: mamba activate r_env #IMPORTANT_NOTE: rownames of samples.tsv and columns of counts.tsv should algin!!!! Rscript rna_timecourse_bacteria.R \ --counts counts_fixed.tsv \ --samples samples.tsv \ --condition_col condition \ --time_col time_h \ --emapper ~/DATA/Data_JuliaFuchs_RNAseq_2025/eggnog_out.emapper.annotations.txt \ --volcano_csvs contrasts/ctrl_vs_treat.csv \ --outdir results_bacteria -
Import data and pca-plot
#mamba activate r_env #install.packages("ggfun") # Import the required libraries library("AnnotationDbi") library("clusterProfiler") library("ReactomePA") library(gplots) library(tximport) library(DESeq2) #library("org.Hs.eg.db") library(dplyr) library(tidyverse) #install.packages("devtools") #devtools::install_version("gtable", version = "0.3.0") library(gplots) library("RColorBrewer") #install.packages("ggrepel") library("ggrepel") # install.packages("openxlsx") library(openxlsx) library(EnhancedVolcano) library(DESeq2) library(edgeR) setwd("~/DATA/Data_JuliaFuchs_RNAseq_2025/results/star_salmon") # Define paths to your Salmon output quantification files files <- c("Untreated_4h_r1" = "./Untreated_4h_1a/quant.sf", "Untreated_4h_r2" = "./Untreated_4h_1b/quant.sf", "Untreated_4h_r3" = "./Untreated_4h_1c/quant.sf", "Untreated_8h_r1" = "./Untreated_8h_1d/quant.sf", "Untreated_8h_r2" = "./Untreated_8h_1e/quant.sf", "Untreated_8h_r3" = "./Untreated_8h_1f/quant.sf", "Untreated_18h_r1" = "./Untreated_18h_1g/quant.sf", "Untreated_18h_r2" = "./Untreated_18h_1h/quant.sf", "Untreated_18h_r3" = "./Untreated_18h_1i/quant.sf", "Mitomycin_4h_r1" = "./Mitomycin_4h_2a/quant.sf", "Mitomycin_4h_r2" = "./Mitomycin_4h_2b/quant.sf", "Mitomycin_4h_r3" = "./Mitomycin_4h_2c/quant.sf", "Mitomycin_8h_r1" = "./Mitomycin_8h_2d/quant.sf", "Mitomycin_8h_r2" = "./Mitomycin_8h_2e/quant.sf", "Mitomycin_8h_r3" = "./Mitomycin_8h_2f/quant.sf", "Mitomycin_18h_r1" = "./Mitomycin_18h_2g/quant.sf", "Mitomycin_18h_r2" = "./Mitomycin_18h_2h/quant.sf", "Mitomycin_18h_r3" = "./Mitomycin_18h_2i/quant.sf", "Moxi_4h_r1" = "./Moxi_4h_3a/quant.sf", "Moxi_4h_r2" = "./Moxi_4h_3b/quant.sf", "Moxi_4h_r3" = "./Moxi_4h_3c/quant.sf", "Moxi_8h_r1" = "./Moxi_8h_3d/quant.sf", "Moxi_8h_r2" = "./Moxi_8h_3e/quant.sf", "Moxi_8h_r3" = "./Moxi_8h_3f/quant.sf", "Moxi_18h_r1" = "./Moxi_18h_3g/quant.sf", "Moxi_18h_r2" = "./Moxi_18h_3h/quant.sf", "Moxi_18h_r3" = "./Moxi_18h_3i/quant.sf") # Import the transcript abundance data with tximport txi <- tximport(files, type = "salmon", txIn = TRUE, txOut = TRUE) # Define the replicates and condition of the samples replicate <- factor(c("r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3", "r1", "r2", "r3")) condition <- factor(c("Untreated_4h","Untreated_4h","Untreated_4h","Untreated_8h","Untreated_8h","Untreated_8h","Untreated_18h","Untreated_18h","Untreated_18h", "Mitomycin_4h","Mitomycin_4h","Mitomycin_4h","Mitomycin_8h","Mitomycin_8h","Mitomycin_8h","Mitomycin_18h","Mitomycin_18h","Mitomycin_18h", "Moxi_4h","Moxi_4h","Moxi_4h","Moxi_8h","Moxi_8h","Moxi_8h","Moxi_18h","Moxi_18h","Moxi_18h")) # Construct colData manually colData <- data.frame(condition=condition, replicate=replicate, row.names=names(files)) #dds <- DESeqDataSetFromTximport(txi, colData, design = ~ condition + batch) dds <- DESeqDataSetFromTximport(txi, colData, design = ~ condition) # -- Save the rlog-transformed counts -- dim(counts(dds)) head(counts(dds), 10) rld <- rlogTransformation(dds) rlog_counts <- assay(rld) write.xlsx(as.data.frame(rlog_counts), "gene_rlog_transformed_counts.xlsx") # -- pca -- png("pca2.png", 1200, 800) plotPCA(rld, intgroup=c("condition")) dev.off() png("pca3.png", 1200, 800) plotPCA(rld, intgroup=c("replicate")) dev.off() pdat <- plotPCA(rld, intgroup = c("condition","replicate"), returnData = TRUE) percentVar <- round(100 * attr(pdat, "percentVar")) # 1) keep only non-WT samples #pdat <- subset(pdat, !grepl("^WT_", condition)) # drop unused factor levels so empty WT facets disappear pdat$condition <- droplevels(pdat$condition) # 2) pretty condition names: deltaadeIJ -> ΔadeIJ pdat$condition <- gsub("^deltaadeIJ", "\u0394adeIJ", pdat$condition) png("pca4.png", 1200, 800) ggplot(pdat, aes(PC1, PC2, color = replicate)) + geom_point(size = 3) + facet_wrap(~ condition) + xlab(paste0("PC1: ", percentVar[1], "% variance")) + ylab(paste0("PC2: ", percentVar[2], "% variance")) + theme_classic() dev.off() pdat <- plotPCA(rld, intgroup = c("condition","replicate"), returnData = TRUE) percentVar <- round(100 * attr(pdat, "percentVar")) # Drop WT_* conditions from the data and from factor levels pdat <- subset(pdat, !grepl("^WT_", condition)) pdat$condition <- droplevels(pdat$condition) # Prettify condition labels for the legend: deltaadeIJ -> ΔadeIJ pdat$condition <- gsub("^deltaadeIJ", "\u0394adeIJ", pdat$condition) p <- ggplot(pdat, aes(PC1, PC2, color = replicate, shape = condition)) + geom_point(size = 3) + xlab(paste0("PC1: ", percentVar[1], "% variance")) + ylab(paste0("PC2: ", percentVar[2], "% variance")) + theme_classic() png("pca5.png", 1200, 800); print(p); dev.off() pdat <- plotPCA(rld, intgroup = c("condition","replicate"), returnData = TRUE) percentVar <- round(100 * attr(pdat, "percentVar")) p_fac <- ggplot(pdat, aes(PC1, PC2, color = replicate)) + geom_point(size = 3) + facet_wrap(~ condition) + xlab(paste0("PC1: ", percentVar[1], "% variance")) + ylab(paste0("PC2: ", percentVar[2], "% variance")) + theme_classic() png("pca6.png", 1200, 800); print(p_fac); dev.off() # -- heatmap -- png("heatmap2.png", 1200, 800) distsRL <- dist(t(assay(rld))) mat <- as.matrix(distsRL) hc <- hclust(distsRL) hmcol <- colorRampPalette(brewer.pal(9,"GnBu"))(100) heatmap.2(mat, Rowv=as.dendrogram(hc),symm=TRUE, trace="none",col = rev(hmcol), margin=c(13, 13)) dev.off() # -- pca_media_strain -- #png("pca_media.png", 1200, 800) #plotPCA(rld, intgroup=c("media")) #dev.off() #png("pca_strain.png", 1200, 800) #plotPCA(rld, intgroup=c("strain")) #dev.off() #png("pca_time.png", 1200, 800) #plotPCA(rld, intgroup=c("time")) #dev.off() # ------------------------ # 1️⃣ Setup and input files # ------------------------ # Read in transcript-to-gene mapping tx2gene <- read.table("salmon_tx2gene.tsv", header=FALSE, stringsAsFactors=FALSE) colnames(tx2gene) <- c("transcript_id", "gene_id", "gene_name") # Prepare tx2gene for gene-level summarization (remove gene_name if needed) tx2gene_geneonly <- tx2gene[, c("transcript_id", "gene_id")] # -------------------------------- # 4️⃣ Raw counts table (with gene names) # -------------------------------- # Extract raw gene-level counts counts_data <- as.data.frame(counts(dds, normalized=FALSE)) counts_data$gene_id <- rownames(counts_data) # Add gene names tx2gene_unique <- unique(tx2gene[, c("gene_id", "gene_name")]) counts_data <- merge(counts_data, tx2gene_unique, by="gene_id", all.x=TRUE) # Reorder columns: gene_id, gene_name, then counts count_cols <- setdiff(colnames(counts_data), c("gene_id", "gene_name")) counts_data <- counts_data[, c("gene_id", "gene_name", count_cols)] # -------------------------------- # 5️⃣ Calculate CPM # -------------------------------- library(edgeR) library(openxlsx) # Prepare count matrix for CPM calculation count_matrix <- as.matrix(counts_data[, !(colnames(counts_data) %in% c("gene_id", "gene_name"))]) # Calculate CPM #cpm_matrix <- cpm(count_matrix, normalized.lib.sizes=FALSE) total_counts <- colSums(count_matrix) cpm_matrix <- t(t(count_matrix) / total_counts) * 1e6 cpm_matrix <- as.data.frame(cpm_matrix) # Add gene_id and gene_name back to CPM table cpm_counts <- cbind(counts_data[, c("gene_id", "gene_name")], cpm_matrix) # -------------------------------- # 6️⃣ Save outputs # -------------------------------- write.csv(counts_data, "gene_raw_counts.csv", row.names=FALSE) write.xlsx(counts_data, "gene_raw_counts.xlsx", row.names=FALSE) write.xlsx(cpm_counts, "gene_cpm_counts.xlsx", row.names=FALSE) -
Select the differentially expressed genes
#https://galaxyproject.eu/posts/2020/08/22/three-steps-to-galaxify-your-tool/ #https://www.biostars.org/p/282295/ #https://www.biostars.org/p/335751/ dds$condition # [1] Untreated_4h Untreated_4h Untreated_4h Untreated_8h Untreated_8h # [6] Untreated_8h Untreated_18h Untreated_18h Untreated_18h Mitomycin_4h # [11] Mitomycin_4h Mitomycin_4h Mitomycin_8h Mitomycin_8h Mitomycin_8h # [16] Mitomycin_18h Mitomycin_18h Mitomycin_18h Moxi_4h Moxi_4h # [21] Moxi_4h Moxi_8h Moxi_8h Moxi_8h Moxi_18h # [26] Moxi_18h Moxi_18h # 9 Levels: Mitomycin_18h Mitomycin_4h Mitomycin_8h Moxi_18h Moxi_4h ... Untreated_8h #CONSOLE: mkdir star_salmon/degenes setwd("degenes") # Construct colData automatically sample_table <- data.frame( condition = condition, replicate = replicate ) split_cond <- do.call(rbind, strsplit(as.character(condition), "_")) #colnames(split_cond) <- c("genotype", "exposure", "time") colnames(split_cond) <- c("genotype", "time") colData <- cbind(sample_table, split_cond) colData$genotype <- factor(colData$genotype) #colData$exposure <- factor(colData$exposure) colData$time <- factor(colData$time) #colData$group <- factor(paste(colData$genotype, colData$exposure, colData$time, sep = "_")) colData$group <- factor(paste(colData$genotype, colData$time, sep = "_")) colData2 <- data.frame(condition=condition, row.names=names(files)) # 确保因子顺序(可选) colData$genotype <- relevel(factor(colData$genotype), ref = "Untreated") #colData$exposure <- relevel(factor(colData$exposure), ref = "none") colData$time <- relevel(factor(colData$time), ref = "4h") dds <- DESeqDataSetFromTximport(txi, colData, design = ~ genotype * time) dds <- DESeq(dds, betaPrior = FALSE) resultsNames(dds) #[1] "Intercept" "genotype_Mitomycin_vs_Untreated" #[3] "genotype_Moxi_vs_Untreated" "time_18h_vs_4h" #[5] "time_8h_vs_4h" "genotypeMitomycin.time18h" #[7] "genotypeMoxi.time18h" "genotypeMitomycin.time8h" #[9] "genotypeMoxi.time8h" #Mitomycin(丝裂霉素)通常特指丝裂霉素C(Mitomycin C, MMC),是一类来自放线菌(Streptomyces)的抗肿瘤抗生素。它在体内被还原后转化为活性烷化剂,可与DNA发生交联,阻断复制与转录,从而抑制细胞增殖。 #一句话理解:Mitomycin C 是一种能让DNA“粘住”的抗癌药,既可全身化疗,也常被医生小剂量局部用来防止疤痕组织长回来。 # 提取 genotype 的主效应: up 489, down 67 contrast <- "genotype_Mitomycin_vs_Untreated" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) #莫西沙星(Moxifloxacin)是一种第四代氟喹诺酮类抗生素,常见商品名如 Avelox(口服/静脉)与 Vigamox(0.5% 眼用滴剂)。 #作用机制: 抑制细菌的DNA 回旋酶(DNA gyrase)和拓扑异构酶 IV,阻断细菌 DNA 复制与修复,属杀菌作用。 # 提取 genotype 的主效应: up 349, down 118 contrast <- "genotype_Moxi_vs_Untreated" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) # 提取 time 的主效应 up 262; down 51 contrast <- "time_18h_vs_4h" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) # 提取 time 的主效应 up 90; down 18 contrast <- "time_8h_vs_4h" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) colData$genotype <- relevel(factor(colData$genotype), ref = "Moxi") colData$time <- relevel(factor(colData$time), ref = "8h") dds <- DESeqDataSetFromTximport(txi, colData, design = ~ genotype * time) dds <- DESeq(dds, betaPrior = FALSE) resultsNames(dds) #[1] "Intercept" "genotype_Untreated_vs_Moxi" #[3] "genotype_Mitomycin_vs_Moxi" "time_4h_vs_8h" #[5] "time_18h_vs_8h" "genotypeUntreated.time4h" #[7] "genotypeMitomycin.time4h" "genotypeUntreated.time18h" #[9] "genotypeMitomycin.time18h" # 提取 genotype 的主效应: up 361, down 6 contrast <- "genotype_Mitomycin_vs_Moxi" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) # 提取 time 的主效应 up 15; down 3 contrast <- "time_18h_vs_8h" res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(contrast, "all.txt", sep="-")) up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(contrast, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(contrast, "down.txt", sep="-")) #1.) Moxi_4h_vs_Untreated_4h #2.) Mitomycin_4h_vs_Untreated_4h #3.) Moxi_8h_vs_Untreated_8h #4.) Mitomycin_8h_vs_Untreated_8h #5.) Moxi_18h_vs_Untreated_18h #6.) Mitomycin_18h_vs_Untreated_18h #---- relevel to control ---- dds <- DESeqDataSetFromTximport(txi, colData, design = ~ condition) dds$condition <- relevel(dds$condition, "Untreated_4h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Moxi_4h_vs_Untreated_4h", "Mitomycin_4h_vs_Untreated_4h") dds$condition <- relevel(dds$condition, "Untreated_8h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Moxi_8h_vs_Untreated_8h", "Mitomycin_8h_vs_Untreated_8h") dds$condition <- relevel(dds$condition, "Untreated_18h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Moxi_18h_vs_Untreated_18h", "Mitomycin_18h_vs_Untreated_18h") # Mitomycin_xh dds$condition <- relevel(dds$condition, "Mitomycin_4h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Mitomycin_18h_vs_Mitomycin_4h", "Mitomycin_8h_vs_Mitomycin_4h") dds$condition <- relevel(dds$condition, "Mitomycin_8h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Mitomycin_18h_vs_Mitomycin_8h") # Moxi_xh dds$condition <- relevel(dds$condition, "Moxi_4h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Moxi_18h_vs_Moxi_4h", "Moxi_8h_vs_Moxi_4h") dds$condition <- relevel(dds$condition, "Moxi_8h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Moxi_18h_vs_Moxi_8h") # Untreated_xh dds$condition <- relevel(dds$condition, "Untreated_4h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Untreated_18h_vs_Untreated_4h", "Untreated_8h_vs_Untreated_4h") dds$condition <- relevel(dds$condition, "Untreated_8h") dds = DESeq(dds, betaPrior=FALSE) resultsNames(dds) clist <- c("Untreated_18h_vs_Untreated_8h") for (i in clist) { contrast = paste("condition", i, sep="_") #for_Mac_vs_LB contrast = paste("media", i, sep="_") res = results(dds, name=contrast) res <- res[!is.na(res$log2FoldChange),] res_df <- as.data.frame(res) write.csv(as.data.frame(res_df[order(res_df$pvalue),]), file = paste(i, "all.txt", sep="-")) #res$log2FoldChange < -2 & res$padj < 5e-2 up <- subset(res_df, padj<=0.05 & log2FoldChange>=2) down <- subset(res_df, padj<=0.05 & log2FoldChange<=-2) write.csv(as.data.frame(up[order(up$log2FoldChange,decreasing=TRUE),]), file = paste(i, "up.txt", sep="-")) write.csv(as.data.frame(down[order(abs(down$log2FoldChange),decreasing=TRUE),]), file = paste(i, "down.txt", sep="-")) } # -- Under host-env (mamba activate plot-numpy1) -- mamba activate plot-numpy1 grep -P "\tgene\t" CP052959_m.gff > CP052959_gene.gff #NOTE that the script replace_gene_names.py was improved with a single fallback rule: after the initial mapping, any still empty/NA GeneName will be filled with the GeneID stripped of the gene-/rna- prefix. Nothing else changes. for cmp in Mitomycin_18h_vs_Untreated_18h Mitomycin_8h_vs_Untreated_8h Mitomycin_4h_vs_Untreated_4h Moxi_18h_vs_Untreated_18h Moxi_8h_vs_Untreated_8h Moxi_4h_vs_Untreated_4h Mitomycin_18h_vs_Mitomycin_4h Mitomycin_18h_vs_Mitomycin_8h Mitomycin_8h_vs_Mitomycin_4h Moxi_18h_vs_Moxi_4h Moxi_18h_vs_Moxi_8h Moxi_8h_vs_Moxi_4h Untreated_18h_vs_Untreated_4h Untreated_18h_vs_Untreated_8h Untreated_8h_vs_Untreated_4h; do python3 ~/Scripts/replace_gene_names.py /home/jhuang/DATA/Data_JuliaFuchs_RNAseq_2025/CP052959_gene.gff ${cmp}-all.txt ${cmp}-all.csv python3 ~/Scripts/replace_gene_names.py /home/jhuang/DATA/Data_JuliaFuchs_RNAseq_2025/CP052959_gene.gff ${cmp}-up.txt ${cmp}-up.csv python3 ~/Scripts/replace_gene_names.py /home/jhuang/DATA/Data_JuliaFuchs_RNAseq_2025/CP052959_gene.gff ${cmp}-down.txt ${cmp}-down.csv done #deltaadeIJ_none_24_vs_deltaadeIJ_none_17 up(0) down(0) #deltaadeIJ_one_24_vs_deltaadeIJ_one_17 up(0) down(8: gabT, H0N29_11475, H0N29_01015, H0N29_01030, ...) #deltaadeIJ_two_24_vs_deltaadeIJ_two_17 up(8) down(51) -
(NOT_PERFORMED) Volcano plots
# ---- delta sbp TSB 2h vs WT TSB 2h ---- res <- read.csv("Mitomycin_18h_vs_Untreated_18h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] #print(duplicated_genes) # [1] "bfr" "lipA" "ahpF" "pcaF" "alr" "pcaD" "cydB" "lpdA" "pgaC" "ppk1" #[11] "pcaF" "tuf" "galE" "murI" "yccS" "rrf" "rrf" "arsB" "ptsP" "umuD" #[21] "map" "pgaB" "rrf" "rrf" "rrf" "pgaD" "uraH" "benE" #res[res$GeneName == "bfr", ] #1st_strategy First occurrence is kept and Subsequent duplicates are removed #res <- res[!duplicated(res$GeneName), ] #2nd_strategy keep the row with the smallest padj value for each GeneName res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Mitomycin_18h_vs_Untreated_18h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) ## Ensure the data frame matches the expected format ## For example, it should have columns: log2FoldChange, padj, etc. #res <- as.data.frame(res) ## Remove rows with NA in log2FoldChange (if needed) #res <- res[!is.na(res$log2FoldChange),] # Replace padj = 0 with a small value #NO_SUCH_RECORDS: res$padj[res$padj == 0] <- 1e-150 #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Mitomycin_18h_vs_Untreated_18h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Mitomycin_18h_vs_Untreated_18h")) dev.off() # ---- delta sbp TSB 4h vs WT TSB 4h ---- res <- read.csv("deltasbp_TSB_4h_vs_WT_TSB_4h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Δsbp_TSB_4h_vs_WT_TSB_4h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Δsbp_TSB_4h_vs_WT_TSB_4h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Δsbp TSB 4h versus WT TSB 4h")) dev.off() # ---- delta sbp TSB 18h vs WT TSB 18h ---- res <- read.csv("deltasbp_TSB_18h_vs_WT_TSB_18h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Δsbp_TSB_18h_vs_WT_TSB_18h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Δsbp_TSB_18h_vs_WT_TSB_18h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Δsbp TSB 18h versus WT TSB 18h")) dev.off() # ---- delta sbp MH 2h vs WT MH 2h ---- res <- read.csv("deltasbp_MH_2h_vs_WT_MH_2h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] #print(duplicated_genes) # [1] "bfr" "lipA" "ahpF" "pcaF" "alr" "pcaD" "cydB" "lpdA" "pgaC" "ppk1" #[11] "pcaF" "tuf" "galE" "murI" "yccS" "rrf" "rrf" "arsB" "ptsP" "umuD" #[21] "map" "pgaB" "rrf" "rrf" "rrf" "pgaD" "uraH" "benE" #res[res$GeneName == "bfr", ] #1st_strategy First occurrence is kept and Subsequent duplicates are removed #res <- res[!duplicated(res$GeneName), ] #2nd_strategy keep the row with the smallest padj value for each GeneName res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Δsbp_MH_2h_vs_WT_MH_2h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) ## Ensure the data frame matches the expected format ## For example, it should have columns: log2FoldChange, padj, etc. #res <- as.data.frame(res) ## Remove rows with NA in log2FoldChange (if needed) #res <- res[!is.na(res$log2FoldChange),] # Replace padj = 0 with a small value #NO_SUCH_RECORDS: res$padj[res$padj == 0] <- 1e-150 #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Δsbp_MH_2h_vs_WT_MH_2h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Δsbp MH 2h versus WT MH 2h")) dev.off() # ---- delta sbp MH 4h vs WT MH 4h ---- res <- read.csv("deltasbp_MH_4h_vs_WT_MH_4h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Δsbp_MH_4h_vs_WT_MH_4h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Δsbp_MH_4h_vs_WT_MH_4h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Δsbp MH 4h versus WT MH 4h")) dev.off() # ---- delta sbp MH 18h vs WT MH 18h ---- res <- read.csv("deltasbp_MH_18h_vs_WT_MH_18h-all.csv") # Replace empty GeneName with modified GeneID res$GeneName <- ifelse( res$GeneName == "" | is.na(res$GeneName), gsub("gene-", "", res$GeneID), res$GeneName ) duplicated_genes <- res[duplicated(res$GeneName), "GeneName"] res <- res %>% group_by(GeneName) %>% slice_min(padj, with_ties = FALSE) %>% ungroup() res <- as.data.frame(res) # Sort res first by padj (ascending) and then by log2FoldChange (descending) res <- res[order(res$padj, -res$log2FoldChange), ] # Assuming res is your dataframe and already processed # Filter up-regulated genes: log2FoldChange > 2 and padj < 5e-2 up_regulated <- res[res$log2FoldChange > 2 & res$padj < 5e-2, ] # Filter down-regulated genes: log2FoldChange < -2 and padj < 5e-2 down_regulated <- res[res$log2FoldChange < -2 & res$padj < 5e-2, ] # Create a new workbook wb <- createWorkbook() # Add the complete dataset as the first sheet addWorksheet(wb, "Complete_Data") writeData(wb, "Complete_Data", res) # Add the up-regulated genes as the second sheet addWorksheet(wb, "Up_Regulated") writeData(wb, "Up_Regulated", up_regulated) # Add the down-regulated genes as the third sheet addWorksheet(wb, "Down_Regulated") writeData(wb, "Down_Regulated", down_regulated) # Save the workbook to a file saveWorkbook(wb, "Gene_Expression_Δsbp_MH_18h_vs_WT_MH_18h.xlsx", overwrite = TRUE) # Set the 'GeneName' column as row.names rownames(res) <- res$GeneName # Drop the 'GeneName' column since it's now the row names res$GeneName <- NULL head(res) #library(EnhancedVolcano) # Assuming res is already sorted and processed png("Δsbp_MH_18h_vs_WT_MH_18h.png", width=1200, height=1200) #max.overlaps = 10 EnhancedVolcano(res, lab = rownames(res), x = 'log2FoldChange', y = 'padj', pCutoff = 5e-2, FCcutoff = 2, title = '', subtitleLabSize = 18, pointSize = 3.0, labSize = 5.0, colAlpha = 1, legendIconSize = 4.0, drawConnectors = TRUE, widthConnectors = 0.5, colConnectors = 'black', subtitle = expression("Δsbp MH 18h versus WT MH 18h")) dev.off() #Annotate the Gene_Expression_xxx_vs_yyy.xlsx in the next steps (see below e.g. Gene_Expression_with_Annotations_Urine_vs_MHB.xlsx)
KEGG and GO annotations in non-model organisms
https://www.biobam.com/functional-analysis/

10.1. Assign KEGG and GO Terms (see diagram above)
Since your organism is non-model, standard R databases (org.Hs.eg.db, etc.) won’t work. You’ll need to manually retrieve KEGG and GO annotations.
Option 1 (KEGG Terms): EggNog based on orthology and phylogenies
EggNOG-mapper assigns both KEGG Orthology (KO) IDs and GO terms.
Install EggNOG-mapper:
mamba create -n eggnog_env python=3.8 eggnog-mapper -c conda-forge -c bioconda #eggnog-mapper_2.1.12
mamba activate eggnog_env
Run annotation:
#diamond makedb --in eggnog6.prots.faa -d eggnog_proteins.dmnd
mkdir /home/jhuang/mambaforge/envs/eggnog_env/lib/python3.8/site-packages/data/
download_eggnog_data.py --dbname eggnog.db -y --data_dir /home/jhuang/mambaforge/envs/eggnog_env/lib/python3.8/site-packages/data/
#NOT_WORKING: emapper.py -i CP052959_gene.fasta -o eggnog_dmnd_out --cpu 60 -m diamond[hmmer,mmseqs] --dmnd_db /home/jhuang/REFs/eggnog_data/data/eggnog_proteins.dmnd
#Download the protein sequences from Genbank
mv ~/Downloads/sequence\(10\).txt CP052959_protein_.fasta
python ~/Scripts/update_fasta_header.py CP052959_protein_.fasta CP052959_protein.fasta
emapper.py -i CP052959_protein.fasta -o eggnog_out --cpu 20 #--resume
#----> result annotations.tsv: Contains KEGG, GO, and other functional annotations.
#----> 470.IX87_14445:
* 470 likely refers to the organism or strain (e.g., Acinetobacter baumannii ATCC 19606 or another related strain).
* IX87_14445 would refer to a specific gene or protein within that genome.
Extract KEGG KO IDs from annotations.emapper.annotations.
Option 2 (GO Terms from 'Blast2GO 5 Basic', saved in blast2go_annot.annot and blast2go_annot.annot2): Using Blast/Diamond + Blast2GO_GUI based on sequence alignment + GO mapping
* jhuang@WS-2290C:~/DATA/Data_JuliaFuchs_RNAseq_2025$ ~/Tools/Blast2GO/Blast2GO_Launcher setting the workspace "mkdir ~/b2gWorkspace_JuliaFuchs_RNAseq_2025; cp /mnt/md1/DATA/Data_JuliaFuchs_RNAseq_2025/CP052959_protein.fasta ~/b2gWorkspace_JuliaFuchs_RNAseq_2025;"
# ------ STEP_1: 100% Load Sequences (CP052959_protein): done ------
* Button 'File' --> 'Load' --> 'Load Sequences' --> 'Load Fasta File (.fasta)' Choose a protein sequence file (e.g. CP052959_protein.fasta) (Tags: NONE, generated columns: Nr, SeqName) as input
# ------ STEP_2: 100% QBlast (CP052959_protein): done with warnings [4-5 days]; similar to DAMIAN and the most time-consuming step is blastn/blastp ------
* Button 'blast' at the NCBI (Parameters: blastp, nr, ...) (Tags: BLASTED, generated columns: Description, Length, #Hits, e-Value, sim mean),
-- QBlast (CP052959_protein) Warning! --
QBlast finished with warnings!
Blasted Sequences: 2011
Sequences without results: 99
Check the Job log for details and try to submit again.
Restarting QBlast may result in additional results, depending on the error type.
"Blast (CP052959_protein) Done"
# ------ STEP_3: 100% Mapping (CP052959_protein): done [3h56m10s] ------
* Button 'mapping' (Tags: MAPPED, generated columns: #GO, GO IDs, GO Names)
-- Mapping (CP052959_protein) Done --
"Mapping finished - Please proceed now to annotation."
# ------ STEP_4: 100% Annotation (CP052959_protein): done [7m56s] ------
* Button 'annot' (Tags: ANNOTATED, generated columns: Enzyme Codes, Enzyme Names)
* Used parameter 'Annotation CutOff': The Blast2GO Annotation Rule seeks to find the most specific GO annotations with a certain level of reliability. An annotation score is calculated for each candidate GO which is composed by the sequence similarity of the Blast Hit, the evidence code of the source GO and the position of the particular GO in the Gene Ontology hierarchy. This annotation score cutoff select the most specific GO term for a given GO branch which lies above this value.
* Used parameter 'GO Weight' is a value which is added to Annotation Score of a more general/abstract Gene Ontology term for each of its more specific, original source GO terms. In this case, more general GO terms which summarise many original source terms (those ones directly associated to the Blast Hits) will have a higher Annotation Score.
-- Annotation (CP052959_protein) Done --
"Annotation finished."
#(NOT_USED) or blast2go_cli_v1.5.1
#https://help.biobam.com/space/BCD/2250407989/Installation
#see ~/Scripts/blast2go_pipeline.sh
# ------ STEP_5: 100% Export Annotations (CP052959_protein): done (for before_merging) ------
+ Button 'File' -> 'Export' -> 'Export Annotations' -> 'Export Annotations (.annot, custom, etc.)' as ~/b2gWorkspace_JuliaFuchs_RNAseq_2025/blast2go_annot.annot.
+ Option 3 (GO Terms from 'Blast2GO 5 Basic' using interpro): Interpro based protein families / domains --> Button interpro, Export Format XML (e.g. HJI06_00260.xml) to Folder "/home/jhuang/b2gWorkspace_JuliaFuchs_RNAseq_2025"
# ------ STEP_6: 100% InterProSacn (CP052959_protein): done [1d6h41m51s] ------
* Button 'interpro' (Tags: INTERPRO, generated columns: InterPro IDs, InterPro GO IDs, InterPro GO Names)
-- InterProScan Finished, You can now merge the obtained GO Annotations. --
"InterProScan (CP052959_protein) Done"
"InterProScan Finished - You can now merge the obtained GO Annotations."
+ MERGE the results of InterPro GO IDs (Option 3) to GO IDs (Option 2) and generate final GO IDs
# ------ STEP_7: 100% Merge InterProScan GOs to Annotation (CP052959_protein): done [1s] ------
* Button 'interpro'/'Merge InterProScan GOs to Annotation' --> "Merge (add and validate) all GO terms retrieved via InterProScan to the already existing GO annotation."
-- Merge InterProScan GOs to Annotation (CP052959_protein) Done --
"Finished merging GO terms from InterPro with annotations."
"Maybe you want to run ANNEX (Annotation Augmentation)."
#* (NOT_USED) Button 'annot'/'ANNEX' --> "ANNEX finished. Maybe you want to do the next step: Enzyme Code Mapping."
# ------ STEP_8: 100% Export Annotations (CP052959_protein): done (for after_merging) ------
+ Button 'File' -> 'Export' -> 'Export Annotations' -> 'Export Annotations (.annot, custom, etc.)' as ~/b2gWorkspace_JuliaFuchs_RNAseq_2025/blast2go_annot.annot2.
#NOTE that annotations are different between before_merging and after_merging; after_merging has more annotation-items.
#-- before merging (blast2go_annot.annot) --
#H0N29_18790 GO:0004842 ankyrin repeat domain-containing protein
#H0N29_18790 GO:0085020
#None for HJI06_00005
#-- after merging (blast2go_annot.annot2) -->
#H0N29_18790 GO:0031436 ankyrin repeat domain-containing protein
#H0N29_18790 GO:0070531
#H0N29_18790 GO:0004842
#H0N29_18790 GO:0005515
#H0N29_18790 GO:0085020
#HJI06_00005 GO:0005737 chromosomal replication initiator protein DnaA
#HJI06_00005 GO:0005886
#HJI06_00005 GO:0003688
#HJI06_00005 GO:0005524
#HJI06_00005 GO:0008289
#HJI06_00005 GO:0016887
#HJI06_00005 GO:0006270
#HJI06_00005 GO:0006275
#HJI06_00005 EC:3.6.1
#HJI06_00005 EC:3.6
#HJI06_00005 EC:3
#HJI06_00005 EC:3.6.1.15
Option 4 (NOT_USED): RFAM for non-colding RNA
Option 5 (NOT_USED): PSORTb for subcellular localizations
Option 6 (NOT_USED): KAAS (KEGG Automatic Annotation Server)
* Go to KAAS
* Upload your FASTA file.
* Select an appropriate gene set.
* Download the KO assignments.10.2. Find the Closest KEGG Organism Code (NOT_USED)
Since your species isn't directly in KEGG, use a closely related organism.
* Check available KEGG organisms:
library(clusterProfiler)
library(KEGGREST)
kegg_organisms <- keggList("organism")
Pick the closest relative (e.g., zebrafish "dre" for fish, Arabidopsis "ath" for plants).
# Search for Acinetobacter in the list
grep("Acinetobacter", kegg_organisms, ignore.case = TRUE, value = TRUE)
# Gammaproteobacteria
#Extract KO IDs from the eggnog results for "Acinetobacter baumannii strain ATCC 19606"10.3. Find the Closest KEGG Organism for a Non-Model Species (NOT_USED)
If your organism is not in KEGG, search for the closest relative:
grep("fish", kegg_organisms, ignore.case = TRUE, value = TRUE) # Example search
For KEGG pathway enrichment in non-model species, use "ko" instead of a species code (the code has been intergrated in the point 4):
kegg_enrich <- enrichKEGG(gene = gene_list, organism = "ko") # "ko" = KEGG Orthology10.4. Perform KEGG and GO Enrichment in R (under dir ~/DATA/Data_Tam_RNAseq_2025_subMIC_exposure_ATCC19606/results/star_salmon/degenes)
#BiocManager::install("GO.db")
#BiocManager::install("AnnotationDbi")
# Load required libraries
library(openxlsx) # For Excel file handling
library(dplyr) # For data manipulation
library(tidyr)
library(stringr)
library(clusterProfiler) # For KEGG and GO enrichment analysis
#library(org.Hs.eg.db) # Replace with appropriate organism database
library(GO.db)
library(AnnotationDbi)
setwd("~/DATA/Data_Tam_RNAseq_2025_subMIC_exposure_ATCC19606/results/star_salmon/degenes")
# PREPARING go_terms and ec_terms: annot_* file: cut -f1-2 -d$'\t' blast2go_annot.annot2 > blast2go_annot.annot2_
# PREPARING eggnog_out.emapper.annotations.txt from eggnog_out.emapper.annotations by removing ## lines at the beginning and END and renaming #query to query
#(plot-numpy1) jhuang@WS-2290C:~/DATA/Data_JuliaFuchs_RNAseq_2025$ diff eggnog_out.emapper.annotations eggnog_out.emapper.annotations.txt
#1,5c1
#< ## Thu Jan 30 16:34:52 2025
#< ## emapper-2.1.12
#< ## /home/jhuang/mambaforge/envs/eggnog_env/bin/emapper.py -i CP059040_protein.fasta -o eggnog_out --cpu 60
#< ##
#< #query seed_ortholog evalue score eggNOG_OGs max_annot_lvl COG_category Description Preferred_name GOs EC KEGG_ko KEGG_Pathway KEGG_Module KEGG_Reaction KEGG_rclass BRITE KEGG_TC CAZy BiGG_Reaction PFAMs
#---
#> query seed_ortholog evalue score eggNOG_OGs max_annot_lvl COG_category Description Preferred_name GOs EC KEGG_ko KEGG_Pathway KEGG_Module KEGG_Reaction KEGG_rclass BRITE KEGG_TC CAZy BiGG_Reaction PFAMs
#3620,3622d3615
#< ## 3614 queries scanned
#< ## Total time (seconds): 8.176708459854126
# Step 1: Load the blast2go annotation file with a check for missing columns
annot_df <- read.table("/home/jhuang/b2gWorkspace_JuliaFuchs_RNAseq_2025/blast2go_annot.annot2_", header = FALSE, sep = "\t", stringsAsFactors = FALSE, fill = TRUE)
# If the structure is inconsistent, we can make sure there are exactly 3 columns:
colnames(annot_df) <- c("GeneID", "Term")
# Step 2: Filter and aggregate GO and EC terms as before
go_terms <- annot_df %>%
filter(grepl("^GO:", Term)) %>%
group_by(GeneID) %>%
summarize(GOs = paste(Term, collapse = ","), .groups = "drop")
ec_terms <- annot_df %>%
filter(grepl("^EC:", Term)) %>%
group_by(GeneID) %>%
summarize(EC = paste(Term, collapse = ","), .groups = "drop")
# Key Improvements:
# * Looped processing of all 6 input files to avoid redundancy.
# * Robust handling of empty KEGG and GO enrichment results to prevent contamination of results between iterations.
# * File-safe output: Each dataset creates a separate Excel workbook with enriched sheets only if data exists.
# * Error handling for GO term descriptions via tryCatch.
# * Improved clarity and modular structure for easier maintenance and future additions.
#file_name = "deltasbp_TSB_2h_vs_WT_TSB_2h-all.csv"
# ---------------------- Generated DEG(Annotated)_KEGG_GO_* -----------------------
suppressPackageStartupMessages({
library(readr)
library(dplyr)
library(stringr)
library(tidyr)
library(openxlsx)
library(clusterProfiler)
library(AnnotationDbi)
library(GO.db)
})
# ---- PARAMETERS ----
PADJ_CUT <- 5e-2
LFC_CUT <- 2
# Your emapper annotations (with columns: query, GOs, EC, KEGG_ko, KEGG_Pathway, KEGG_Module, ... )
emapper_path <- "~/DATA/Data_JuliaFuchs_RNAseq_2025/eggnog_out.emapper.annotations.txt"
# Input files (you can add/remove here)
input_files <- c(
"Mitomycin_18h_vs_Untreated_18h-all.csv", #up 576, down 307 --> height 11000
"Mitomycin_8h_vs_Untreated_8h-all.csv", #up 580, down 201 --> height 11000
"Mitomycin_4h_vs_Untreated_4h-all.csv", #up 489, down 67 --> height 6400
"Moxi_18h_vs_Untreated_18h-all.csv", #up 472, down 317 --> height 10500
"Moxi_8h_vs_Untreated_8h-all.csv", #up 486, down 307 --> height 10500
"Moxi_4h_vs_Untreated_4h-all.csv", #up 349, down 118 --> height 6400
"Untreated_18h_vs_Untreated_4h-all.csv", #(up 262, down 51)
"Untreated_18h_vs_Untreated_8h-all.csv", #(up 124, down 26)
"Untreated_8h_vs_Untreated_4h-all.csv", #(up 90, down 18) --> in total 368 --> height 5000
"Mitomycin_18h_vs_Mitomycin_4h-all.csv", #(up 161, down 63)
"Mitomycin_18h_vs_Mitomycin_8h-all.csv", #(up 61, down 28)
"Mitomycin_8h_vs_Mitomycin_4h-all.csv", #(up 47, down 10) --> in total 279 --> height 3500
"Moxi_18h_vs_Moxi_4h-all.csv", #(up 141, down 29)
"Moxi_18h_vs_Moxi_8h-all.csv", #(up 15, down 3)
"Moxi_8h_vs_Moxi_4h-all.csv" #(up 67, down 2) --> in total 196 --> height 2600
)
# ---- HELPERS ----
# Robust reader (CSV first, then TSV)
read_table_any <- function(path) {
tb <- tryCatch(readr::read_csv(path, show_col_types = FALSE),
error = function(e) tryCatch(readr::read_tsv(path, col_types = cols()),
error = function(e2) NULL))
tb
}
# Return a nice Excel-safe base name
xlsx_name_from_file <- function(path) {
base <- tools::file_path_sans_ext(basename(path))
paste0("DEG_KEGG_GO_", base, ".xlsx")
}
# KEGG expand helper: replace K-numbers with GeneIDs using mapping from the same result table
expand_kegg_geneIDs <- function(kegg_res, mapping_tbl) {
if (is.null(kegg_res) || nrow(as.data.frame(kegg_res)) == 0) return(data.frame())
kdf <- as.data.frame(kegg_res)
if (!"geneID" %in% names(kdf)) return(kdf)
# mapping_tbl: columns KEGG_ko (possibly multiple separated by commas) and GeneID
map_clean <- mapping_tbl %>%
dplyr::select(KEGG_ko, GeneID) %>%
filter(!is.na(KEGG_ko), KEGG_ko != "-") %>%
mutate(KEGG_ko = str_remove_all(KEGG_ko, "ko:")) %>%
tidyr::separate_rows(KEGG_ko, sep = ",") %>%
distinct()
if (!nrow(map_clean)) {
return(kdf)
}
expanded <- kdf %>%
tidyr::separate_rows(geneID, sep = "/") %>%
dplyr::left_join(map_clean, by = c("geneID" = "KEGG_ko"), relationship = "many-to-many") %>%
distinct() %>%
dplyr::group_by(ID) %>%
dplyr::summarise(across(everything(), ~ paste(unique(na.omit(.)), collapse = "/")), .groups = "drop")
kdf %>%
dplyr::select(-geneID) %>%
dplyr::left_join(expanded %>% dplyr::select(ID, GeneID), by = "ID") %>%
dplyr::rename(geneID = GeneID)
}
# ---- LOAD emapper annotations ----
eggnog_data <- read.delim(emapper_path, header = TRUE, sep = "\t", quote = "", check.names = FALSE)
# Ensure character columns for joins
eggnog_data$query <- as.character(eggnog_data$query)
eggnog_data$GOs <- as.character(eggnog_data$GOs)
eggnog_data$EC <- as.character(eggnog_data$EC)
eggnog_data$KEGG_ko <- as.character(eggnog_data$KEGG_ko)
# ---- MAIN LOOP ----
for (f in input_files) {
if (!file.exists(f)) { message("Missing: ", f); next }
message("Processing: ", f)
res <- read_table_any(f)
if (is.null(res) || nrow(res) == 0) { message("Empty/unreadable: ", f); next }
# Coerce expected columns if present
if ("padj" %in% names(res)) res$padj <- suppressWarnings(as.numeric(res$padj))
if ("log2FoldChange" %in% names(res)) res$log2FoldChange <- suppressWarnings(as.numeric(res$log2FoldChange))
# Ensure GeneID & GeneName exist
if (!"GeneID" %in% names(res)) {
# Try to infer from a generic 'gene' column
if ("gene" %in% names(res)) res$GeneID <- as.character(res$gene) else res$GeneID <- NA_character_
}
if (!"GeneName" %in% names(res)) res$GeneName <- NA_character_
# Fill missing GeneName from GeneID (drop "gene-")
res$GeneName <- ifelse(is.na(res$GeneName) | res$GeneName == "",
gsub("^gene-", "", as.character(res$GeneID)),
as.character(res$GeneName))
# De-duplicate by GeneName, keep smallest padj
if (!"padj" %in% names(res)) res$padj <- NA_real_
res <- res %>%
group_by(GeneName) %>%
slice_min(padj, with_ties = FALSE) %>%
ungroup() %>%
as.data.frame()
# Sort by padj asc, then log2FC desc
if (!"log2FoldChange" %in% names(res)) res$log2FoldChange <- NA_real_
res <- res[order(res$padj, -res$log2FoldChange), , drop = FALSE]
# Join emapper (strip "gene-" from GeneID to match emapper 'query')
res$GeneID_plain <- gsub("^gene-", "", res$GeneID)
res_ann <- res %>%
left_join(eggnog_data, by = c("GeneID_plain" = "query"))
# --- Split by UP/DOWN using your volcano cutoffs ---
up_regulated <- res_ann %>% filter(!is.na(padj), padj < PADJ_CUT, log2FoldChange > LFC_CUT)
down_regulated <- res_ann %>% filter(!is.na(padj), padj < PADJ_CUT, log2FoldChange < -LFC_CUT)
# --- KEGG enrichment (using K numbers in KEGG_ko) ---
# Prepare KO lists (remove "ko:" if present)
k_up <- up_regulated$KEGG_ko; k_up <- k_up[!is.na(k_up)]
k_dn <- down_regulated$KEGG_ko; k_dn <- k_dn[!is.na(k_dn)]
k_up <- gsub("ko:", "", k_up); k_dn <- gsub("ko:", "", k_dn)
# BREAK_LINE
kegg_up <- tryCatch(enrichKEGG(gene = k_up, organism = "ko"), error = function(e) NULL)
kegg_down <- tryCatch(enrichKEGG(gene = k_dn, organism = "ko"), error = function(e) NULL)
# Convert KEGG K-numbers to your GeneIDs (using mapping from the same result set)
kegg_up_df <- expand_kegg_geneIDs(kegg_up, up_regulated)
kegg_down_df <- expand_kegg_geneIDs(kegg_down, down_regulated)
# --- GO enrichment (custom TERM2GENE built from emapper GOs) ---
# Background gene set = all genes in this comparison
background_genes <- unique(res_ann$GeneID_plain)
# TERM2GENE table (GO -> GeneID_plain)
go_annotation <- res_ann %>%
dplyr::select(GeneID_plain, GOs) %>%
mutate(GOs = ifelse(is.na(GOs), "", GOs)) %>%
tidyr::separate_rows(GOs, sep = ",") %>%
filter(GOs != "") %>%
dplyr::select(GOs, GeneID_plain) %>%
distinct()
# Gene lists for GO enricher
go_list_up <- unique(up_regulated$GeneID_plain)
go_list_down <- unique(down_regulated$GeneID_plain)
go_up <- tryCatch(
enricher(gene = go_list_up, TERM2GENE = go_annotation,
pvalueCutoff = 0.05, pAdjustMethod = "BH",
universe = background_genes),
error = function(e) NULL
)
go_down <- tryCatch(
enricher(gene = go_list_down, TERM2GENE = go_annotation,
pvalueCutoff = 0.05, pAdjustMethod = "BH",
universe = background_genes),
error = function(e) NULL
)
go_up_df <- if (!is.null(go_up)) as.data.frame(go_up) else data.frame()
go_down_df <- if (!is.null(go_down)) as.data.frame(go_down) else data.frame()
# Add GO term descriptions via GO.db (best-effort)
add_go_term_desc <- function(df) {
if (!nrow(df) || !"ID" %in% names(df)) return(df)
df$Description <- sapply(df$ID, function(go_id) {
term <- tryCatch(AnnotationDbi::select(GO.db, keys = go_id,
columns = "TERM", keytype = "GOID"),
error = function(e) NULL)
if (!is.null(term) && nrow(term)) term$TERM[1] else NA_character_
})
df
}
go_up_df <- add_go_term_desc(go_up_df)
go_down_df <- add_go_term_desc(go_down_df)
# ---- Write Excel workbook ----
out_xlsx <- xlsx_name_from_file(f)
wb <- createWorkbook()
addWorksheet(wb, "Complete")
writeData(wb, "Complete", res_ann)
addWorksheet(wb, "Up_Regulated")
writeData(wb, "Up_Regulated", up_regulated)
addWorksheet(wb, "Down_Regulated")
writeData(wb, "Down_Regulated", down_regulated)
addWorksheet(wb, "KEGG_Enrichment_Up")
writeData(wb, "KEGG_Enrichment_Up", kegg_up_df)
addWorksheet(wb, "KEGG_Enrichment_Down")
writeData(wb, "KEGG_Enrichment_Down", kegg_down_df)
addWorksheet(wb, "GO_Enrichment_Up")
writeData(wb, "GO_Enrichment_Up", go_up_df)
addWorksheet(wb, "GO_Enrichment_Down")
writeData(wb, "GO_Enrichment_Down", go_down_df)
saveWorkbook(wb, out_xlsx, overwrite = TRUE)
message("Saved: ", out_xlsx)
}10.5. (TODO) Draw the Venn diagram to compare the total DEGs across AUM, Urine, and MHB, irrespective of up- or down-regulation.
library(openxlsx)
# Function to read and clean gene ID files
read_gene_ids <- function(file_path) {
# Read the gene IDs from the file
gene_ids <- readLines(file_path)
# Remove any quotes and trim whitespaces
gene_ids <- gsub('"', '', gene_ids) # Remove quotes
gene_ids <- trimws(gene_ids) # Trim whitespaces
# Remove empty entries or NAs
gene_ids <- gene_ids[gene_ids != "" & !is.na(gene_ids)]
return(gene_ids)
}
# Example list of LB files with both -up.id and -down.id for each condition
lb_files_up <- c("LB.AB_vs_LB.WT19606-up.id", "LB.IJ_vs_LB.WT19606-up.id",
"LB.W1_vs_LB.WT19606-up.id", "LB.Y1_vs_LB.WT19606-up.id")
lb_files_down <- c("LB.AB_vs_LB.WT19606-down.id", "LB.IJ_vs_LB.WT19606-down.id",
"LB.W1_vs_LB.WT19606-down.id", "LB.Y1_vs_LB.WT19606-down.id")
# Combine both up and down files for each condition
lb_files <- c(lb_files_up, lb_files_down)
# Read gene IDs for each file in LB group
#lb_degs <- setNames(lapply(lb_files, read_gene_ids), gsub("-(up|down).id", "", lb_files))
lb_degs <- setNames(lapply(lb_files, read_gene_ids), make.unique(gsub("-(up|down).id", "", lb_files)))
lb_degs_ <- list()
combined_set <- c(lb_degs[["LB.AB_vs_LB.WT19606"]], lb_degs[["LB.AB_vs_LB.WT19606.1"]])
#unique_combined_set <- unique(combined_set)
lb_degs_$AB <- combined_set
combined_set <- c(lb_degs[["LB.IJ_vs_LB.WT19606"]], lb_degs[["LB.IJ_vs_LB.WT19606.1"]])
lb_degs_$IJ <- combined_set
combined_set <- c(lb_degs[["LB.W1_vs_LB.WT19606"]], lb_degs[["LB.W1_vs_LB.WT19606.1"]])
lb_degs_$W1 <- combined_set
combined_set <- c(lb_degs[["LB.Y1_vs_LB.WT19606"]], lb_degs[["LB.Y1_vs_LB.WT19606.1"]])
lb_degs_$Y1 <- combined_set
# Example list of Mac files with both -up.id and -down.id for each condition
mac_files_up <- c("Mac.AB_vs_Mac.WT19606-up.id", "Mac.IJ_vs_Mac.WT19606-up.id",
"Mac.W1_vs_Mac.WT19606-up.id", "Mac.Y1_vs_Mac.WT19606-up.id")
mac_files_down <- c("Mac.AB_vs_Mac.WT19606-down.id", "Mac.IJ_vs_Mac.WT19606-down.id",
"Mac.W1_vs_Mac.WT19606-down.id", "Mac.Y1_vs_Mac.WT19606-down.id")
# Combine both up and down files for each condition in Mac group
mac_files <- c(mac_files_up, mac_files_down)
# Read gene IDs for each file in Mac group
mac_degs <- setNames(lapply(mac_files, read_gene_ids), make.unique(gsub("-(up|down).id", "", mac_files)))
mac_degs_ <- list()
combined_set <- c(mac_degs[["Mac.AB_vs_Mac.WT19606"]], mac_degs[["Mac.AB_vs_Mac.WT19606.1"]])
mac_degs_$AB <- combined_set
combined_set <- c(mac_degs[["Mac.IJ_vs_Mac.WT19606"]], mac_degs[["Mac.IJ_vs_Mac.WT19606.1"]])
mac_degs_$IJ <- combined_set
combined_set <- c(mac_degs[["Mac.W1_vs_Mac.WT19606"]], mac_degs[["Mac.W1_vs_Mac.WT19606.1"]])
mac_degs_$W1 <- combined_set
combined_set <- c(mac_degs[["Mac.Y1_vs_Mac.WT19606"]], mac_degs[["Mac.Y1_vs_Mac.WT19606.1"]])
mac_degs_$Y1 <- combined_set
# Function to clean sheet names to ensure no sheet name exceeds 31 characters
truncate_sheet_name <- function(names_list) {
sapply(names_list, function(name) {
if (nchar(name) > 31) {
return(substr(name, 1, 31)) # Truncate sheet name to 31 characters
}
return(name)
})
}
# Assuming lb_degs_ is already a list of gene sets (LB.AB, LB.IJ, etc.)
# Define intersections between different conditions for LB
inter_lb_ab_ij <- intersect(lb_degs_$AB, lb_degs_$IJ)
inter_lb_ab_w1 <- intersect(lb_degs_$AB, lb_degs_$W1)
inter_lb_ab_y1 <- intersect(lb_degs_$AB, lb_degs_$Y1)
inter_lb_ij_w1 <- intersect(lb_degs_$IJ, lb_degs_$W1)
inter_lb_ij_y1 <- intersect(lb_degs_$IJ, lb_degs_$Y1)
inter_lb_w1_y1 <- intersect(lb_degs_$W1, lb_degs_$Y1)
# Define intersections between three conditions for LB
inter_lb_ab_ij_w1 <- Reduce(intersect, list(lb_degs_$AB, lb_degs_$IJ, lb_degs_$W1))
inter_lb_ab_ij_y1 <- Reduce(intersect, list(lb_degs_$AB, lb_degs_$IJ, lb_degs_$Y1))
inter_lb_ab_w1_y1 <- Reduce(intersect, list(lb_degs_$AB, lb_degs_$W1, lb_degs_$Y1))
inter_lb_ij_w1_y1 <- Reduce(intersect, list(lb_degs_$IJ, lb_degs_$W1, lb_degs_$Y1))
# Define intersection between all four conditions for LB
inter_lb_ab_ij_w1_y1 <- Reduce(intersect, list(lb_degs_$AB, lb_degs_$IJ, lb_degs_$W1, lb_degs_$Y1))
# Now remove the intersected genes from each original set for LB
venn_list_lb <- list()
# For LB.AB, remove genes that are also in other conditions
venn_list_lb[["LB.AB_only"]] <- setdiff(lb_degs_$AB, union(inter_lb_ab_ij, union(inter_lb_ab_w1, inter_lb_ab_y1)))
# For LB.IJ, remove genes that are also in other conditions
venn_list_lb[["LB.IJ_only"]] <- setdiff(lb_degs_$IJ, union(inter_lb_ab_ij, union(inter_lb_ij_w1, inter_lb_ij_y1)))
# For LB.W1, remove genes that are also in other conditions
venn_list_lb[["LB.W1_only"]] <- setdiff(lb_degs_$W1, union(inter_lb_ab_w1, union(inter_lb_ij_w1, inter_lb_ab_w1_y1)))
# For LB.Y1, remove genes that are also in other conditions
venn_list_lb[["LB.Y1_only"]] <- setdiff(lb_degs_$Y1, union(inter_lb_ab_y1, union(inter_lb_ij_y1, inter_lb_ab_w1_y1)))
# Add the intersections for LB (same as before)
venn_list_lb[["LB.AB_AND_LB.IJ"]] <- inter_lb_ab_ij
venn_list_lb[["LB.AB_AND_LB.W1"]] <- inter_lb_ab_w1
venn_list_lb[["LB.AB_AND_LB.Y1"]] <- inter_lb_ab_y1
venn_list_lb[["LB.IJ_AND_LB.W1"]] <- inter_lb_ij_w1
venn_list_lb[["LB.IJ_AND_LB.Y1"]] <- inter_lb_ij_y1
venn_list_lb[["LB.W1_AND_LB.Y1"]] <- inter_lb_w1_y1
# Define intersections between three conditions for LB
venn_list_lb[["LB.AB_AND_LB.IJ_AND_LB.W1"]] <- inter_lb_ab_ij_w1
venn_list_lb[["LB.AB_AND_LB.IJ_AND_LB.Y1"]] <- inter_lb_ab_ij_y1
venn_list_lb[["LB.AB_AND_LB.W1_AND_LB.Y1"]] <- inter_lb_ab_w1_y1
venn_list_lb[["LB.IJ_AND_LB.W1_AND_LB.Y1"]] <- inter_lb_ij_w1_y1
# Define intersection between all four conditions for LB
venn_list_lb[["LB.AB_AND_LB.IJ_AND_LB.W1_AND_LB.Y1"]] <- inter_lb_ab_ij_w1_y1
# Assuming mac_degs_ is already a list of gene sets (Mac.AB, Mac.IJ, etc.)
# Define intersections between different conditions
inter_mac_ab_ij <- intersect(mac_degs_$AB, mac_degs_$IJ)
inter_mac_ab_w1 <- intersect(mac_degs_$AB, mac_degs_$W1)
inter_mac_ab_y1 <- intersect(mac_degs_$AB, mac_degs_$Y1)
inter_mac_ij_w1 <- intersect(mac_degs_$IJ, mac_degs_$W1)
inter_mac_ij_y1 <- intersect(mac_degs_$IJ, mac_degs_$Y1)
inter_mac_w1_y1 <- intersect(mac_degs_$W1, mac_degs_$Y1)
# Define intersections between three conditions
inter_mac_ab_ij_w1 <- Reduce(intersect, list(mac_degs_$AB, mac_degs_$IJ, mac_degs_$W1))
inter_mac_ab_ij_y1 <- Reduce(intersect, list(mac_degs_$AB, mac_degs_$IJ, mac_degs_$Y1))
inter_mac_ab_w1_y1 <- Reduce(intersect, list(mac_degs_$AB, mac_degs_$W1, mac_degs_$Y1))
inter_mac_ij_w1_y1 <- Reduce(intersect, list(mac_degs_$IJ, mac_degs_$W1, mac_degs_$Y1))
# Define intersection between all four conditions
inter_mac_ab_ij_w1_y1 <- Reduce(intersect, list(mac_degs_$AB, mac_degs_$IJ, mac_degs_$W1, mac_degs_$Y1))
# Now remove the intersected genes from each original set
venn_list_mac <- list()
# For Mac.AB, remove genes that are also in other conditions
venn_list_mac[["Mac.AB_only"]] <- setdiff(mac_degs_$AB, union(inter_mac_ab_ij, union(inter_mac_ab_w1, inter_mac_ab_y1)))
# For Mac.IJ, remove genes that are also in other conditions
venn_list_mac[["Mac.IJ_only"]] <- setdiff(mac_degs_$IJ, union(inter_mac_ab_ij, union(inter_mac_ij_w1, inter_mac_ij_y1)))
# For Mac.W1, remove genes that are also in other conditions
venn_list_mac[["Mac.W1_only"]] <- setdiff(mac_degs_$W1, union(inter_mac_ab_w1, union(inter_mac_ij_w1, inter_mac_ab_w1_y1)))
# For Mac.Y1, remove genes that are also in other conditions
venn_list_mac[["Mac.Y1_only"]] <- setdiff(mac_degs_$Y1, union(inter_mac_ab_y1, union(inter_mac_ij_y1, inter_mac_ab_w1_y1)))
# Add the intersections (same as before)
venn_list_mac[["Mac.AB_AND_Mac.IJ"]] <- inter_mac_ab_ij
venn_list_mac[["Mac.AB_AND_Mac.W1"]] <- inter_mac_ab_w1
venn_list_mac[["Mac.AB_AND_Mac.Y1"]] <- inter_mac_ab_y1
venn_list_mac[["Mac.IJ_AND_Mac.W1"]] <- inter_mac_ij_w1
venn_list_mac[["Mac.IJ_AND_Mac.Y1"]] <- inter_mac_ij_y1
venn_list_mac[["Mac.W1_AND_Mac.Y1"]] <- inter_mac_w1_y1
# Define intersections between three conditions
venn_list_mac[["Mac.AB_AND_Mac.IJ_AND_Mac.W1"]] <- inter_mac_ab_ij_w1
venn_list_mac[["Mac.AB_AND_Mac.IJ_AND_Mac.Y1"]] <- inter_mac_ab_ij_y1
venn_list_mac[["Mac.AB_AND_Mac.W1_AND_Mac.Y1"]] <- inter_mac_ab_w1_y1
venn_list_mac[["Mac.IJ_AND_Mac.W1_AND_Mac.Y1"]] <- inter_mac_ij_w1_y1
# Define intersection between all four conditions
venn_list_mac[["Mac.AB_AND_Mac.IJ_AND_Mac.W1_AND_Mac.Y1"]] <- inter_mac_ab_ij_w1_y1
# Save the gene IDs to Excel for further inspection (optional)
write.xlsx(lb_degs, file = "LB_DEGs.xlsx")
write.xlsx(mac_degs, file = "Mac_DEGs.xlsx")
# Clean sheet names and write the Venn intersection sets for LB and Mac groups into Excel files
write.xlsx(venn_list_lb, file = "Venn_LB_Genes_Intersect.xlsx", sheetName = truncate_sheet_name(names(venn_list_lb)), rowNames = FALSE)
write.xlsx(venn_list_mac, file = "Venn_Mac_Genes_Intersect.xlsx", sheetName = truncate_sheet_name(names(venn_list_mac)), rowNames = FALSE)
# Venn Diagram for LB group
venn1 <- ggvenn(lb_degs_,
fill_color = c("skyblue", "tomato", "gold", "orchid"),
stroke_size = 0.4,
set_name_size = 5)
ggsave("Venn_LB_Genes.png", plot = venn1, width = 7, height = 7, dpi = 300)
# Venn Diagram for Mac group
venn2 <- ggvenn(mac_degs_,
fill_color = c("lightgreen", "slateblue", "plum", "orange"),
stroke_size = 0.4,
set_name_size = 5)
ggsave("Venn_Mac_Genes.png", plot = venn2, width = 7, height = 7, dpi = 300)
cat("✅ All Venn intersection sets exported to Excel successfully.\n")-
Clustering the genes and draw heatmap
-all_annotated.csv” all_path <- paste0(contrast, "-all_annotated.csv") if (file.exists(all_path)) { ann <- read.csv(all_path, stringsAsFactors = FALSE, check.names = FALSE) pick_col <- function(df, candidates) { hit <- intersect(candidates, names(df)) if (length(hit) == 0) return(NA_character_) hit[1] } id_col <- pick_col(ann, c("GeneID","Gene.ID","Gene_Id","Gene","gene_id","LocusTag","locus_tag","ID")) nm_col <- pick_col(ann, c("GeneName","Gene.Name","Gene_Name","Symbol","gene_name","Name","SYMBOL")) if (!is.na(id_col) && !is.na(nm_col)) { ann[[nm_col]][is.na(ann[[nm_col]])] <- "" id2name <- setNames(ann[[nm_col]], ann[[id_col]]) id2name <- id2name[nzchar(id2name)] # drop empty names hits <- match(rownames(datamat), names(id2name)) repl <- ifelse(is.na(hits), rownames(datamat), id2name[hits]) # avoid duplicate labels on the plot labRow_pretty ‘ΔadeIJ’ and nicer spacing labCol_pretty <- colnames(datamat) #labCol_pretty <- gsub("^deltaadeIJ", "\u0394adeIJ", labCol_pretty) labCol_pretty “WT TSB 2h r1” # If you prefer to drop replicate suffixes, uncomment: # labCol_pretty <- gsub(" r\\d+$", "", labCol_pretty) ## 8) Clustering ———————————————– # Row clustering with Pearson distance hr <- hclust(as.dist(1-cor(t(datamat), method="pearson")), method="complete") #row_cor <- suppressWarnings(cor(t(datamat), method = "pearson", use = "pairwise.complete.obs")) #row_cor[!is.finite(row_cor)] <- 0 #hr <- hclust(as.dist(1 – row_cor), method = "complete") # Color row-side groups by cutting the dendrogram mycl <- cutree(hr, h = max(hr$height) / 1.1) palette_base <- c("yellow","blue","orange","magenta","cyan","red","green","maroon", "lightblue","pink","purple","lightcyan","salmon","lightgreen") mycol <- palette_base[(as.vector(mycl) – 1) %% length(palette_base) + 1] #BREAK_LINE labRow_pretty <- sub("^gene-", "", labRow_pretty) labRow_pretty <- sub("^rna-", "", labRow_pretty) png(paste0("DEGs_heatmap_", contrast, ".png"), width=800, height=600) heatmap.2(datamat, Rowv = as.dendrogram(hr), col = bluered(75), scale = "row", RowSideColors = mycol, trace = "none", margin = c(10, 20), # bottom, left sepwidth = c(0, 0), dendrogram = 'row', Colv = 'false', density.info = 'none', labRow = labRow_pretty, # row labels WITHOUT "gene-" labCol = labCol_pretty, # col labels with Δsbp + spaces cexRow = 2.5, cexCol = 2.5, srtCol = 15, lhei = c(0.6, 4), # enlarge the first number when reduce the plot size to avoid the error 'Error in plot.new() : figure margins too large' lwid = c(0.8, 4)) # enlarge the first number when reduce the plot size to avoid the error 'Error in plot.new() : figure margins too large' dev.off() # DEBUG for some items starting with "gene-" labRow_pretty <- sub("^gene-", "", labRow_pretty) labRow_pretty <- sub("^rna-", "", labRow_pretty) png(paste0("DEGs_heatmap_", contrast, ".png"), width = 800, height = 6500) heatmap.2( datamat, Rowv = as.dendrogram(hr), Colv = FALSE, dendrogram = "row", col = bluered(75), scale = "row", trace = "none", density.info = "none", RowSideColors = mycol, margins = c(10, 15), # c(bottom, left) sepwidth = c(0, 0), labRow = labRow_pretty, labCol = labCol_pretty, cexRow = 1.4, # ↓ smaller column label font (was 1.3) cexCol = 1.8, srtCol = 15, lhei = c(0.01, 4), lwid = c(0.5, 4), key = FALSE # safer; add manual z-score key if you want (see note below) ) dev.off() # —————— Heatmap generation for three samples ———————- ## ============================================================ ## Three-condition DEGs heatmap from multiple pairwise contrasts ## Example contrasts: ## "WT_MH_4h_vs_WT_MH_2h", ## "WT_MH_18h_vs_WT_MH_2h", ## "WT_MH_18h_vs_WT_MH_4h" ## Output shows the union of DEGs across all contrasts and ## only the columns (samples) for the 3 conditions. ## ============================================================ ## ——– 0) User inputs ———————————— contrasts in total 368 –> height 5000 ) contrasts in total 279 –> height 3500 ) contrasts in total 196 –> height 2600 ) ## Optionally force a condition display order (defaults to order of first appearance) cond_order <- c("Untreated_4h","Untreated_8h","Untreated_18h") cond_order <- c("Mitomycin_4h","Mitomycin_8h","Mitomycin_18h") cond_order <- c("Moxi_4h","Moxi_8h","Moxi_18h") #cond_order <- NULL ## ——– 1) Packages ————————————— need <- c("gplots") to_install <- setdiff(need, rownames(installed.packages())) if (length(to_install)) install.packages(to_install, repos = "https://cloud.r-project.org") suppressPackageStartupMessages(library(gplots)) ## ——– 2) Helpers —————————————- read_ids_from_file <- function(path) { if (!file.exists(path)) stop("File not found: ", path) df = 1) { ids <- if ("Gene_Id" %in% names(df)) df[["Gene_Id"]] else df[[1]] } else { df2 <- read.table(path, header = FALSE, stringsAsFactors = FALSE, quote = "\"'", comment.char = "") ids <- df2[[1]] } ids <- trimws(gsub('"', "", ids)) ids[nzchar(ids)] } # From "A_vs_B" return c("A","B") split_contrast_groups <- function(x) { parts <- strsplit(x, "_vs_", fixed = TRUE)[[1]] if (length(parts) != 2L) stop("Contrast must be 'GroupA_vs_GroupB': ", x) parts } # Grep whole tag between start/end or underscores match_tags <- function(nms, tags) { pat <- paste0("(^|_)(?:", paste(tags, collapse = "|"), ")(_|$)") grepl(pat, nms, perl = TRUE) } # Pretty labels for columns (optional tweaks) prettify_col_labels <- function(x) { x <- gsub("^deltasbp", "\u0394sbp", x) # example from your earlier case x <- gsub("_", " ", x) x } # BREAK_LINE # — RUN the code with the new contract from HERE after first run — ## ——– 3) Build GOI (union across contrasts) ————- up_files <- paste0(contrasts, "-up.id") down_files <- paste0(contrasts, "-down.id") GOI <- unique(unlist(c( lapply(up_files, read_ids_from_file), lapply(down_files, read_ids_from_file) ))) if (!length(GOI)) stop("No gene IDs found in any up/down .id files for the given contrasts.") ## ——– 4) Expression matrix (rld or vsd) —————– if (exists("rld")) { expr_all <- assay(rld) } else if (exists("vsd")) { expr_all <- assay(vsd) } else { stop("Neither 'rld' nor 'vsd' object is available in the environment.") } expr_all <- as.matrix(expr_all) present <- intersect(rownames(expr_all), GOI) if (!length(present)) stop("None of the GOI were found among the rownames of the expression matrix.") missing <- setdiff(GOI, present) if (length(missing)) message("Note: ", length(missing), " GOI not found and will be skipped.") ## ——– 5) Infer the THREE condition tags —————– pair_groups <- lapply(contrasts, split_contrast_groups) # list of c(A,B) cond_tags <- unique(unlist(pair_groups)) if (length(cond_tags) != 3L) { stop("Expected exactly three unique condition tags across the contrasts, got: ", paste(cond_tags, collapse = ", ")) } # If user provided an explicit order, use it; else keep first-appearance order if (!is.null(cond_order)) { if (!setequal(cond_order, cond_tags)) stop("cond_order must contain exactly these tags: ", paste(cond_tags, collapse = ", ")) cond_tags <- cond_order } #BREAK_LINE ## ——– 6) Subset columns to those 3 conditions ———– # helper: does a name contain any of the tags? match_any_tag <- function(nms, tags) { pat <- paste0("(^|_)(?:", paste(tags, collapse = "|"), ")(_|$)") grepl(pat, nms, perl = TRUE) } # helper: return the specific tag that a single name matches detect_tag <- function(nm, tags) { hits <- vapply(tags, function(t) grepl(paste0("(^|_)", t, "(_|$)"), nm, perl = TRUE), logical(1)) if (!any(hits)) NA_character_ else tags[which(hits)[1]] } keep_cols <- match_any_tag(colnames(expr_all), cond_tags) if (!any(keep_cols)) { stop("No columns matched any of the three condition tags: ", paste(cond_tags, collapse = ", ")) } sub_idx <- which(keep_cols) sub_colnames <- colnames(expr_all)[sub_idx] # find the tag for each kept column (this is the part that was wrong before) cond_for_col <- vapply(sub_colnames, detect_tag, character(1), tags = cond_tags) # rank columns by your desired condition order, then by name within each condition cond_rank <- match(cond_for_col, cond_tags) ord <- order(cond_rank, sub_colnames) expr_sub <- expr_all[present, sub_idx, drop = FALSE][, ord, drop = FALSE] ## ——– 7) Remove constant/NA rows ———————— row_ok 0) if (any(!row_ok)) message(“Removing “, sum(!row_ok), ” constant/NA rows.”) datamat <- expr_sub[row_ok, , drop = FALSE] ## ——– 8) Labels —————————————- labRow_pretty <- rownames(datamat) # —- Replace GeneID with GeneName from " -all_annotated.csv” all_path <- paste0(contrast, "-all_annotated.csv") if (file.exists(all_path)) { ann <- read.csv(all_path, stringsAsFactors = FALSE, check.names = FALSE) pick_col <- function(df, candidates) { hit <- intersect(candidates, names(df)) if (length(hit) == 0) return(NA_character_) hit[1] } id_col <- pick_col(ann, c("GeneID","Gene.ID","Gene_Id","Gene","gene_id","LocusTag","locus_tag","ID")) nm_col <- pick_col(ann, c("GeneName","Gene.Name","Gene_Name","Symbol","gene_name","Name","SYMBOL")) if (!is.na(id_col) && !is.na(nm_col)) { ann[[nm_col]][is.na(ann[[nm_col]])] <- "" id2name <- setNames(ann[[nm_col]], ann[[id_col]]) id2name <- id2name[nzchar(id2name)] # drop empty names hits <- match(rownames(datamat), names(id2name)) repl <- ifelse(is.na(hits), rownames(datamat), id2name[hits]) # avoid duplicate labels on the plot labRow_pretty <- make.unique(repl, sep = "_") } else { warning("Could not find GeneID/GeneName columns in ", all_path) } } else { warning("File not found: ", all_path) } labCol_pretty <- prettify_col_labels(colnames(datamat)) #BREAK_LINE ## ——– 9) Clustering (rows) —————————— hr <- hclust(as.dist(1 – cor(t(datamat), method = "pearson")), method = "complete") # Color row-side groups by cutting the dendrogram mycl <- cutree(hr, h = max(hr$height) / 1.3) palette_base <- c("yellow","blue","orange","magenta","cyan","red","green","maroon", "lightblue","pink","purple","lightcyan","salmon","lightgreen") mycol <- palette_base[(as.vector(mycl) – 1) %% length(palette_base) + 1] ## ——– 10) Save the matrix used ————————– out_tag <- paste(cond_tags, collapse = "_") write.csv(as.data.frame(datamat), file = paste0("DEGs_heatmap_expression_data_", out_tag, ".txt"), quote = FALSE) ## ——– 11) Plot heatmap ———————————- labRow_pretty <- sub("^gene-", "", labRow_pretty) labRow_pretty ids #add Gene_Id in the first line, delete the “” #Note that using GeneID as index, rather than GeneName, since .txt contains only GeneID. GOI <- read.csv("ids")$Gene_Id RNASeq.NoCellLine <- assay(rld) #install.packages("gplots") library("gplots") #clustering methods: "ward.D", "ward.D2", "single", "complete", "average" (= UPGMA), "mcquitty" (= WPGMA), "median" (= WPGMC) or "centroid" (= UPGMC). pearson or spearman datamat = RNASeq.NoCellLine[GOI, ] #datamat = RNASeq.NoCellLine write.csv(as.data.frame(datamat), file ="DEGs_heatmap_expression_data.txt") constant_rows <- apply(datamat, 1, function(row) var(row) == 0) if(any(constant_rows)) { cat("Removing", sum(constant_rows), "constant rows.\n") datamat <- datamat[!constant_rows, ] } hr <- hclust(as.dist(1-cor(t(datamat), method="pearson")), method="complete") hc <- hclust(as.dist(1-cor(datamat, method="spearman")), method="complete") mycl = cutree(hr, h=max(hr$height)/1.1) mycol = c("YELLOW", "BLUE", "ORANGE", "MAGENTA", "CYAN", "RED", "GREEN", "MAROON", "LIGHTBLUE", "PINK", "MAGENTA", "LIGHTCYAN", "LIGHTRED", "LIGHTGREEN"); mycol = mycol[as.vector(mycl)] png("DEGs_heatmap_deltasbp_TSB_2h_vs_WT_TSB_2h.png", width=1200, height=2000) heatmap.2(datamat, Rowv = as.dendrogram(hr), col = bluered(75), scale = "row", RowSideColors = mycol, trace = "none", margin = c(10, 15), # bottom, left sepwidth = c(0, 0), dendrogram = 'row', Colv = 'false', density.info = 'none', labRow = rownames(datamat), cexRow = 1.5, cexCol = 1.5, srtCol = 35, lhei = c(0.2, 4), # reduce top space (was 1 or more) lwid = c(0.4, 4)) # reduce left space (was 1 or more) dev.off() # ————– Cluster members —————- write.csv(names(subset(mycl, mycl == '1')),file='cluster1_YELLOW.txt') write.csv(names(subset(mycl, mycl == '2')),file='cluster2_DARKBLUE.txt') write.csv(names(subset(mycl, mycl == '3')),file='cluster3_DARKORANGE.txt') write.csv(names(subset(mycl, mycl == '4')),file='cluster4_DARKMAGENTA.txt') write.csv(names(subset(mycl, mycl == '5')),file='cluster5_DARKCYAN.txt') #~/Tools/csv2xls-0.4/csv_to_xls.py cluster*.txt -d',' -o DEGs_heatmap_cluster_members.xls #~/Tools/csv2xls-0.4/csv_to_xls.py DEGs_heatmap_expression_data.txt -d',' -o DEGs_heatmap_expression_data.xls; #### (NOT_WORKING) cluster members (adding annotations, note that it does not work for the bacteria, since it is not model-speices and we cannot use mart=ensembl) ##### subset_1<-names(subset(mycl, mycl == '1')) data <- as.data.frame(datamat[rownames(datamat) %in% subset_1, ]) #2575 subset_2<-names(subset(mycl, mycl == '2')) data <- as.data.frame(datamat[rownames(datamat) %in% subset_2, ]) #1855 subset_3<-names(subset(mycl, mycl == '3')) data <- as.data.frame(datamat[rownames(datamat) %in% subset_3, ]) #217 subset_4<-names(subset(mycl, mycl == '4')) data <- as.data.frame(datamat[rownames(datamat) %in% subset_4, ]) # subset_5<-names(subset(mycl, mycl == '5')) data <- as.data.frame(datamat[rownames(datamat) %in% subset_5, ]) # # Initialize an empty data frame for the annotated data annotated_data <- data.frame() # Determine total number of genes total_genes <- length(rownames(data)) # Loop through each gene to annotate for (i in 1:total_genes) { gene <- rownames(data)[i] result 1) { result <- result[1, ] } # Check if the result is empty if (nrow(result) == 0) { result <- data.frame(ensembl_gene_id = gene, external_gene_name = NA, gene_biotype = NA, entrezgene_id = NA, chromosome_name = NA, start_position = NA, end_position = NA, strand = NA, description = NA) } # Transpose expression values expression_values <- t(data.frame(t(data[gene, ]))) colnames(expression_values) <- colnames(data) # Combine gene information and expression data combined_result <- cbind(result, expression_values) # Append to the final dataframe annotated_data <- rbind(annotated_data, combined_result) # Print progress every 100 genes if (i %% 100 == 0) { cat(sprintf("Processed gene %d out of %d\n", i, total_genes)) } } # Save the annotated data to a new CSV file write.csv(annotated_data, "cluster1_YELLOW.csv", row.names=FALSE) write.csv(annotated_data, "cluster2_DARKBLUE.csv", row.names=FALSE) write.csv(annotated_data, "cluster3_DARKORANGE.csv", row.names=FALSE) write.csv(annotated_data, "cluster4_DARKMAGENTA.csv", row.names=FALSE) write.csv(annotated_data, "cluster5_DARKCYAN.csv", row.names=FALSE) #~/Tools/csv2xls-0.4/csv_to_xls.py cluster*.csv -d',' -o DEGs_heatmap_clusters.xls#http://xgenes.com/article/article-content/150/draw-venn-diagrams-using-matplotlib/ #http://xgenes.com/article/article-content/276/go-terms-for-s-epidermidis/ # save the Up-regulated and Down-regulated genes into -up.id and -down.id for i in Mitomycin_18h_vs_Untreated_18h Mitomycin_8h_vs_Untreated_8h Mitomycin_4h_vs_Untreated_4h Moxi_18h_vs_Untreated_18h Moxi_8h_vs_Untreated_8h Moxi_4h_vs_Untreated_4h Mitomycin_18h_vs_Mitomycin_4h Mitomycin_18h_vs_Mitomycin_8h Mitomycin_8h_vs_Mitomycin_4h Moxi_18h_vs_Moxi_4h Moxi_18h_vs_Moxi_8h Moxi_8h_vs_Moxi_4h Untreated_18h_vs_Untreated_4h Untreated_18h_vs_Untreated_8h Untreated_8h_vs_Untreated_4h; do echo "cut -d',' -f1-1 ${i}-up.txt > ${i}-up.id"; echo "cut -d',' -f1-1 ${i}-down.txt > ${i}-down.id"; done #The row’s description column says “TsaE,” but the preferred_name is ydiB (shikimate/quinate dehydrogenase). #Length = 301 aa — that fits YdiB much better. TsaE (YjeE) is a small P-loop ATPase, typically ~150–170 aa, not ~300 aa. #The COG/orthology hit and the very strong e-value also point to a canonical enzyme rather than the tiny TsaE ATPase. #What likely happened #The “GeneName” (tsaE) was inherited from a prior/automated annotation. #Orthology mapping (preferred_name) recognizes the protein as YdiB; the free-text product line didn’t update, leaving a label clash. #What to do #Treat this locus as ydiB (shikimate dehydrogenase; aka AroE-II), not TsaE. #If you want to be thorough, BLAST the sequence and/or run InterPro/eggNOG: you should see SDR/oxidoreductase motifs for YdiB, not the P-loop NTPase (Walker A) you’d expect for TsaE. #Check your genome for the true t6A genes (tsaB/tsaD/tsaE/tsaC); the real tsaE should be a much smaller ORF. # -- Replace GeneName with Preferred_name when Preferred_name is non-empty and not '-' (first sheet). -- for i in Mitomycin_18h_vs_Untreated_18h Mitomycin_8h_vs_Untreated_8h Mitomycin_4h_vs_Untreated_4h Moxi_18h_vs_Untreated_18h Moxi_8h_vs_Untreated_8h Moxi_4h_vs_Untreated_4h Mitomycin_18h_vs_Mitomycin_4h Mitomycin_18h_vs_Mitomycin_8h Mitomycin_8h_vs_Mitomycin_4h Moxi_18h_vs_Moxi_4h Moxi_18h_vs_Moxi_8h Moxi_8h_vs_Moxi_4h Untreated_18h_vs_Untreated_4h Untreated_18h_vs_Untreated_8h Untreated_8h_vs_Untreated_4h; do python ~/Scripts/replace_with_preferred_name.py DEG_KEGG_GO_${i}-all.xlsx -o ${i}-all_annotated.csv done # ------------------ Heatmap generation for two samples ---------------------- ## ------------------------------------------------------------ ## DEGs heatmap (dynamic GOI + dynamic column tags) ## Example contrast: deltasbp_TSB_2h_vs_WT_TSB_2h ## Assumes 'rld' (or 'vsd') is in the environment (DESeq2 transform) ## ------------------------------------------------------------ #RUN rld generation code (see the first part of the file) setwd("degenes") ## 0) Config --------------------------------------------------- contrast <- "Mitomycin_18h_vs_Untreated_18h" #up 576, down 307 --> height 11000 contrast <- "Mitomycin_8h_vs_Untreated_8h" #up 580, down 201 --> height 11000 contrast <- "Mitomycin_4h_vs_Untreated_4h" #up 489, down 67 --> height 6500 contrast <- "Moxi_18h_vs_Untreated_18h" #up 472, down 317 --> height 10500 contrast <- "Moxi_8h_vs_Untreated_8h" #up 486, down 307 --> height 10500 contrast <- "Moxi_4h_vs_Untreated_4h" #up 349, down 118 --> height 6500 ## 1) Packages ------------------------------------------------- need <- c("gplots") to_install <- setdiff(need, rownames(installed.packages())) if (length(to_install)) install.packages(to_install, repos = "https://cloud.r-project.org") suppressPackageStartupMessages(library(gplots)) ## 2) Helpers -------------------------------------------------- # Read IDs from a file that may be: # - one column with or without header "Gene_Id" # - may contain quotes read_ids_from_file <- function(path) { #path <- up_file if (!file.exists(path)) stop("File not found: ", path) df <- tryCatch( read.table(path, header = TRUE, stringsAsFactors = FALSE, quote = "\"'", comment.char = ""), error = function(e) NULL ) if (!is.null(df) && ncol(df) >= 1) { if ("Gene_Id" %in% names(df)) { ids <- df[["Gene_Id"]] } else if (ncol(df) == 1L) { ids <- df[[1]] } else { first_nonempty <- which(colSums(df != "", na.rm = TRUE) > 0)[1] if (is.na(first_nonempty)) stop("No usable IDs in: ", path) ids <- df[[first_nonempty]] } } else { df2 <- read.table(path, header = FALSE, stringsAsFactors = FALSE, quote = "\"'", comment.char = "") if (ncol(df2) < 1L) stop("No usable IDs in: ", path) ids <- df2[[1]] } ids <- trimws(gsub('"', "", ids)) ids[nzchar(ids)] } #BREAK_LINE # From "A_vs_B" get c("A","B") split_contrast_groups <- function(x) { parts <- strsplit(x, "_vs_", fixed = TRUE)[[1]] if (length(parts) != 2L) stop("Contrast must be in the form 'GroupA_vs_GroupB'") parts } # Match whole tags at boundaries or underscores match_tags <- function(nms, tags) { pat <- paste0("(^|_)(?:", paste(tags, collapse = "|"), ")(_|$)") grepl(pat, nms, perl = TRUE) } ## 3) Expression matrix (DESeq2 rlog/vst) ---------------------- # Use rld if present; otherwise try vsd if (exists("rld")) { expr_all <- assay(rld) } else if (exists("vsd")) { expr_all <- assay(vsd) } else { stop("Neither 'rld' nor 'vsd' object is available in the environment.") } RNASeq.NoCellLine <- as.matrix(expr_all) #colnames(RNASeq.NoCellLine) <- c("WT_none_17_r1", "WT_none_17_r2", "WT_none_17_r3", "WT_none_24_r1", "WT_none_24_r2", "WT_none_24_r3", "deltaadeIJ_none_17_r1", "deltaadeIJ_none_17_r2", "deltaadeIJ_none_17_r3", "deltaadeIJ_none_24_r1", "deltaadeIJ_none_24_r2", "deltaadeIJ_none_24_r3", "WT_one_17_r1", "WT_one_17_r2", "WT_one_17_r3", "WT_one_24_r1", "WT_one_24_r2", "WT_one_24_r3", "deltaadeIJ_one_17_r1", "deltaadeIJ_one_17_r2", "deltaadeIJ_one_17_r3", "deltaadeIJ_one_24_r1", "deltaadeIJ_one_24_r2", "deltaadeIJ_one_24_r3", "WT_two_17_r1", "WT_two_17_r2", "WT_two_17_r3", "WT_two_24_r1", "WT_two_24_r2", "WT_two_24_r3", "deltaadeIJ_two_17_r1", "deltaadeIJ_two_17_r2", "deltaadeIJ_two_17_r3", "deltaadeIJ_two_24_r1", "deltaadeIJ_two_24_r2", "deltaadeIJ_two_24_r3") # -- RUN the code with the new contract from HERE after first run -- ## 4) Build GOI from the two .id files (Note that if empty not run!)------------------------- up_file <- paste0(contrast, "-up.id") down_file <- paste0(contrast, "-down.id") GOI_up <- read_ids_from_file(up_file) GOI_down <- read_ids_from_file(down_file) GOI <- unique(c(GOI_up, GOI_down)) if (length(GOI) == 0) stop("No gene IDs found in up/down .id files.") # GOI are already 'gene-*' in your data — use them directly for matching present <- intersect(rownames(RNASeq.NoCellLine), GOI) if (!length(present)) stop("None of the GOI were found among the rownames of the expression matrix.") # Optional: report truly missing IDs (on the same 'gene-*' format) missing <- setdiff(GOI, present) if (length(missing)) message("Note: ", length(missing), " GOI not found and will be skipped.") ## 5) Keep ONLY columns for the two groups in the contrast ----- groups <- split_contrast_groups(contrast) # e.g., c("deltasbp_TSB_2h", "WT_TSB_2h") keep_cols <- match_tags(colnames(RNASeq.NoCellLine), groups) if (!any(keep_cols)) { stop("No columns matched the contrast groups: ", paste(groups, collapse = " and "), ". Check your column names or implement colData-based filtering.") } cols_idx <- which(keep_cols) sub_colnames <- colnames(RNASeq.NoCellLine)[cols_idx] # Put the second group first (e.g., WT first in 'deltasbp..._vs_WT...') ord <- order(!grepl(paste0("(^|_)", groups[2], "(_|$)"), sub_colnames, perl = TRUE)) # Subset safely expr_sub <- RNASeq.NoCellLine[present, cols_idx, drop = FALSE][, ord, drop = FALSE] ## 6) Remove constant/NA rows ---------------------------------- row_ok <- apply(expr_sub, 1, function(x) is.finite(sum(x)) && var(x, na.rm = TRUE) > 0) if (any(!row_ok)) message("Removing ", sum(!row_ok), " constant/NA rows.") datamat <- expr_sub[row_ok, , drop = FALSE] # Save the filtered matrix used for the heatmap (optional) out_mat <- paste0("DEGs_heatmap_expression_data_", contrast, ".txt") write.csv(as.data.frame(datamat), file = out_mat, quote = FALSE) #BREAK_LINE ## 7) Pretty labels (display only) --------------------------- # Start from rownames(datamat) (assumed to be GeneID) labRow_pretty <- rownames(datamat) # ---- Replace GeneID with GeneName from "