Preparing samplesheet.csv
sample,fastq_1,fastq_2,strandedness
Urine_r1,Urine_r1_R1.fq.gz,Urine_r1_R2.fq.gz,auto
Urine_r2,Urine_r2_R1.fq.gz,Urine_r2_R2.fq.gz,auto
Urine_r3,Urine_r3_R1.fq.gz,Urine_r3_R2.fq.gz,auto
Urine_r4,Urine_r4_R1.fq.gz,Urine_r4_R2.fq.gz,auto
Urine_r5,Urine_r5_R1.fq.gz,Urine_r5_R2.fq.gz,auto
Urine_r6,Urine_r6_R1.fq.gz,Urine_r6_R2.fq.gz,auto
AUM_r1,AUM_r1_R1.fq.gz,AUM_r1_R2.fq.gz,auto
AUM_r2,AUM_r2_R1.fq.gz,AUM_r2_R2.fq.gz,auto
AUM_r3,AUM_r3_R1.fq.gz,AUM_r3_R2.fq.gz,auto
AUM_r4,AUM_r4_R1.fq.gz,AUM_r4_R2.fq.gz,auto
AUM_r5,AUM_r5_R1.fq.gz,AUM_r5_R2.fq.gz,auto
AUM_r6,AUM_r6_R1.fq.gz,AUM_r6_R2.fq.gz,auto
MH_r1,MH_r1_R1.fq.gz,MH_r1_R2.fq.gz,auto
MH_r2,MH_r2_R1.fq.gz,MH_r2_R2.fq.gz,auto
MH_r3,MH_r3_R1.fq.gz,MH_r3_R2.fq.gz,auto
MH_r4,MH_r4_R1.fq.gz,MH_r4_R2.fq.gz,auto
MH_r5,MH_r5_R1.fq.gz,MH_r5_R2.fq.gz,auto
MH_r6,MH_r6_R1.fq.gz,MH_r6_R2.fq.gz,auto
Urine-AZI_r1,Urine-AZI_r1_R1.fq.gz,Urine-AZI_r1_R2.fq.gz,auto
Urine-AZI_r2,Urine-AZI_r2_R1.fq.gz,Urine-AZI_r2_R2.fq.gz,auto
Urine-AZI_r3,Urine-AZI_r3_R1.fq.gz,Urine-AZI_r3_R2.fq.gz,auto
AUM-AZI_r1,AUM-AZI_r1_R1.fq.gz,AUM-AZI_r1_R2.fq.gz,auto
AUM-AZI_r2,AUM-AZI_r2_R1.fq.gz,AUM-AZI_r2_R2.fq.gz,auto
AUM-AZI_r3,AUM-AZI_r3_R1.fq.gz,AUM-AZI_r3_R2.fq.gz,auto
MH-AZI_r1,MH-AZI_r1_R1.fq.gz,MH-AZI_r1_R2.fq.gz,auto
MH-AZI_r2,MH-AZI_r2_R1.fq.gz,MH-AZI_r2_R2.fq.gz,auto
MH-AZI_r3,MH-AZI_r3_R1.fq.gz,MH-AZI_r3_R2.fq.gz,auto
Import data and pca-plot
# ==============================================================================
# ADAPTED PIPELINE: 6 Groups (Urine/AUM/MH ± AZI) -> Counts Export -> PCA
# ==============================================================================
# 1️⃣ LOAD LIBRARIES ------------------------------------------------------------
suppressPackageStartupMessages({
library(DESeq2)
library(tximport)
library(dplyr)
library(ggplot2)
library(ggrepel)
library(edgeR) # For robust CPM calculation
library(openxlsx) # For Excel export
})
# 2️⃣ SET WORKING DIRECTORY & DEFINE SAMPLES ------------------------------------
setwd("/mnt/md1/DATA/Data_Tam_RNAseq_2024_AUM_MHB_Urine_on_ATCC19606/results/star_salmon")
files <- c(
"AUM-AZI_r1" = "./AUM-AZI_r1/quant.sf",
"AUM-AZI_r2" = "./AUM-AZI_r2/quant.sf",
"AUM-AZI_r3" = "./AUM-AZI_r3/quant.sf",
"AUM_r1" = "./AUM_r1/quant.sf",
"AUM_r2" = "./AUM_r2/quant.sf",
"AUM_r3" = "./AUM_r3/quant.sf",
"MH-AZI_r1" = "./MH-AZI_r1/quant.sf",
"MH-AZI_r2" = "./MH-AZI_r2/quant.sf",
"MH-AZI_r3" = "./MH-AZI_r3/quant.sf",
"MH_r1" = "./MH_r1/quant.sf",
"MH_r2" = "./MH_r2/quant.sf",
"MH_r3" = "./MH_r3/quant.sf",
"Urine-AZI_r1" = "./Urine-AZI_r1/quant.sf",
"Urine-AZI_r2" = "./Urine-AZI_r2/quant.sf",
"Urine-AZI_r3" = "./Urine-AZI_r3/quant.sf",
"Urine_r1" = "./Urine_r1/quant.sf",
"Urine_r2" = "./Urine_r2/quant.sf",
"Urine_r3" = "./Urine_r3/quant.sf"
)
# 3️⃣ AUTOMATED METADATA PARSING -----------------------------------------------
# Dynamically extracts Media, Treatment, and Combined Group from filenames
samples <- names(files)
colData <- data.frame(
media = factor(gsub("-.*", "", samples)),
treatment = factor(ifelse(grepl("AZI", samples), "AZI", "Control")),
group = factor(paste(gsub("-.*", "", samples),
ifelse(grepl("AZI", samples), "AZI", "Control"),
sep = "_")),
replicate = as.numeric(gsub(".*r", "", samples)),
row.names = samples,
stringsAsFactors = FALSE
)
# 4️⃣ IMPORT & SUMMARIZE TO GENE LEVEL -----------------------------------------
tx2gene <- read.table("salmon_tx2gene.tsv", header = FALSE, stringsAsFactors = FALSE)
colnames(tx2gene) <- c("transcript_id", "gene_id", "gene_name")
tx2gene_geneonly <- tx2gene[, c("transcript_id", "gene_id")]
# Direct gene-level import (faster & standard for DESeq2)
txi <- tximport(files, type = "salmon", tx2gene = tx2gene_geneonly, txOut = FALSE)
# Build DESeq2 object
dds <- DESeqDataSetFromTximport(txi, colData = colData, design = ~ group)
# Optional: Pre-filter low-count genes (improves VST & PCA stability)
keep <- rowSums(counts(dds) >= 10) >= 3
dds <- dds[keep, ]
# 5️⃣ EXPORT RAW COUNTS & CPM -------------------------------------------------
counts_data <- as.data.frame(counts(dds, normalized = FALSE))
counts_data$gene_id <- rownames(counts_data)
# Merge gene names
tx2gene_unique <- unique(tx2gene[, c("gene_id", "gene_name")])
counts_data <- merge(counts_data, tx2gene_unique, by = "gene_id", all.x = TRUE)
count_cols <- setdiff(colnames(counts_data), c("gene_id", "gene_name"))
counts_data <- counts_data[, c("gene_id", "gene_name", count_cols)]
# Calculate CPM (edgeR handles library size normalization automatically)
cpm_matrix <- edgeR::cpm(as.matrix(counts_data[, count_cols]))
cpm_counts <- cbind(counts_data[, c("gene_id", "gene_name")], as.data.frame(cpm_matrix))
# Save tables
write.csv(counts_data, "gene_raw_counts.csv", row.names = FALSE)
write.xlsx(counts_data, "gene_raw_counts.xlsx", row.names = FALSE)
write.xlsx(cpm_counts, "gene_cpm_counts.xlsx", row.names = FALSE)
cat("✅ Count tables exported successfully.\n")
# ==============================================================================
# 6️⃣ PCA PLOTTING -------------------------------------------------------------
# ==============================================================================
vsd <- vst(dds, blind = FALSE)
pca_data <- plotPCA(vsd, intgroup = c("media", "treatment", "group"), returnData = TRUE)
percent_var <- round(100 * attr(pca_data, "percentVar"))
base_theme <- theme_bw(base_size = 12) +
theme(plot.title = element_text(hjust = 0.5, face = "bold", size = 13),
legend.position = "right",
legend.title = element_text(face = "bold"),
panel.grid.major = element_line(color = "grey90"),
panel.grid.minor = element_blank())
# --- Plot 1: By Culture Media ---
p1 <- ggplot(pca_data, aes(x = PC1, y = PC2, color = media)) +
geom_point(size = 3, alpha = 0.8) +
geom_text_repel(aes(label = name), size = 2.5, max.overlaps = 20, show.legend = FALSE) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: Samples Colored by Media", color = "Media") + base_theme
ggsave("01_PCA_by_Media.png", p1, width = 8, height = 6, dpi = 300)
# --- Plot 2: By Treatment (AZI vs Control) ---
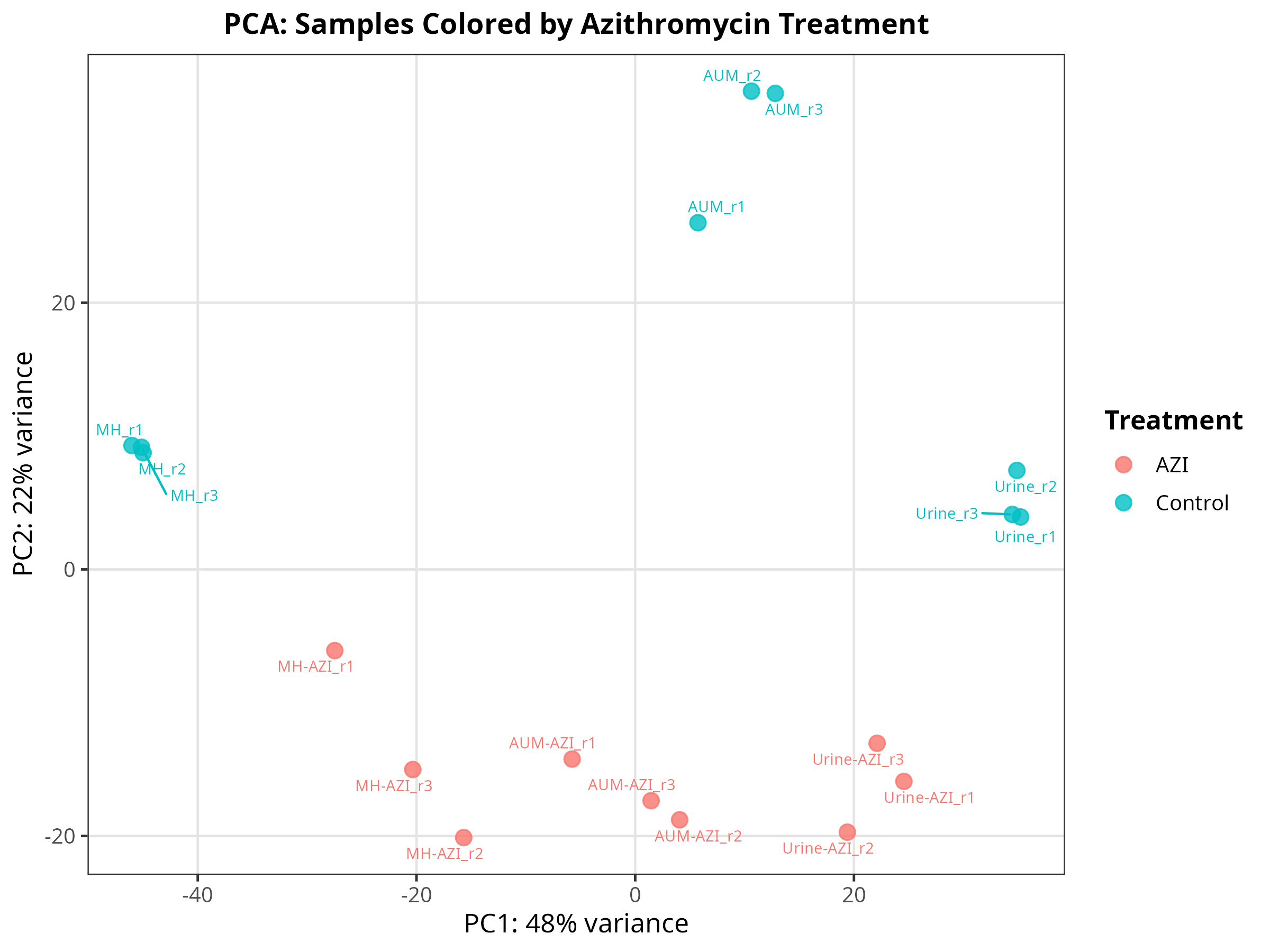
p2 <- ggplot(pca_data, aes(x = PC1, y = PC2, color = treatment)) +
geom_point(size = 3, alpha = 0.8) +
geom_text_repel(aes(label = name), size = 2.5, max.overlaps = 20, show.legend = FALSE) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: Samples Colored by Azithromycin Treatment", color = "Treatment") + base_theme
ggsave("02_PCA_by_Treatment.png", p2, width = 8, height = 6, dpi = 300)
# --- Plot 3: Combined Groups (Labeled) ---
p3 <- ggplot(pca_data, aes(x = PC1, y = PC2, color = group)) +
geom_point(size = 3, alpha = 0.8) +
geom_text_repel(aes(label = name), size = 2.2, max.overlaps = 30, box.padding = 0.3) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: Combined Media × Treatment Groups", color = "Group") + base_theme +
theme(legend.position = "bottom")
ggsave("03_PCA_CombinedGroups.png", p3, width = 9, height = 7, dpi = 300)
# --- Plot 4: 95% Confidence Ellipses (by Media) ---
p4 <- ggplot(pca_data, aes(x = PC1, y = PC2, color = media, fill = media)) +
geom_point(size = 3, alpha = 0.7) +
stat_ellipse(level = 0.95, alpha = 0.2, geom = "polygon", show.legend = FALSE) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: 95% Confidence Ellipses by Media", color = "Media", fill = "Media") + base_theme
ggsave("04_PCA_Ellipses.png", p4, width = 8, height = 6, dpi = 300)
message("✅ All 4 PCA plots saved to working directory!")
# 1. Generate PCA Data
vsd <- vst(dds, blind = FALSE)
pca_data <- plotPCA(vsd, intgroup = c("media", "treatment", "replicate"), returnData = TRUE)
# 2. FIX: Clean the 'media' column (remove _r1, _r2, _r3 suffix)
pca_data$media_clean <- gsub("_r[1-3]$", "", pca_data$media)
# 3. Create Group Variable with cleaned media names
pca_data$Group <- factor(paste(pca_data$media_clean, pca_data$treatment, sep = "_"),
levels = c("Urine_Control", "Urine_AZI",
"AUM_Control", "AUM_AZI",
"MH_Control", "MH_AZI"))
# 4. Convert replicate to factor for shape mapping
pca_data$replicate <- factor(pca_data$replicate, levels = c(1, 2, 3), labels = c("r1", "r2", "r3"))
# 5. Define 6 Colors
my_colors <- c(
"Urine_Control" = "#999999", "Urine_AZI" = "#E41A1C",
"AUM_Control" = "#377EB8", "AUM_AZI" = "#FF7F00",
"MH_Control" = "#4DAF4A", "MH_AZI" = "#984EA3"
)
percent_var <- round(100 * attr(pca_data, "percentVar"))
# 6. Plotting
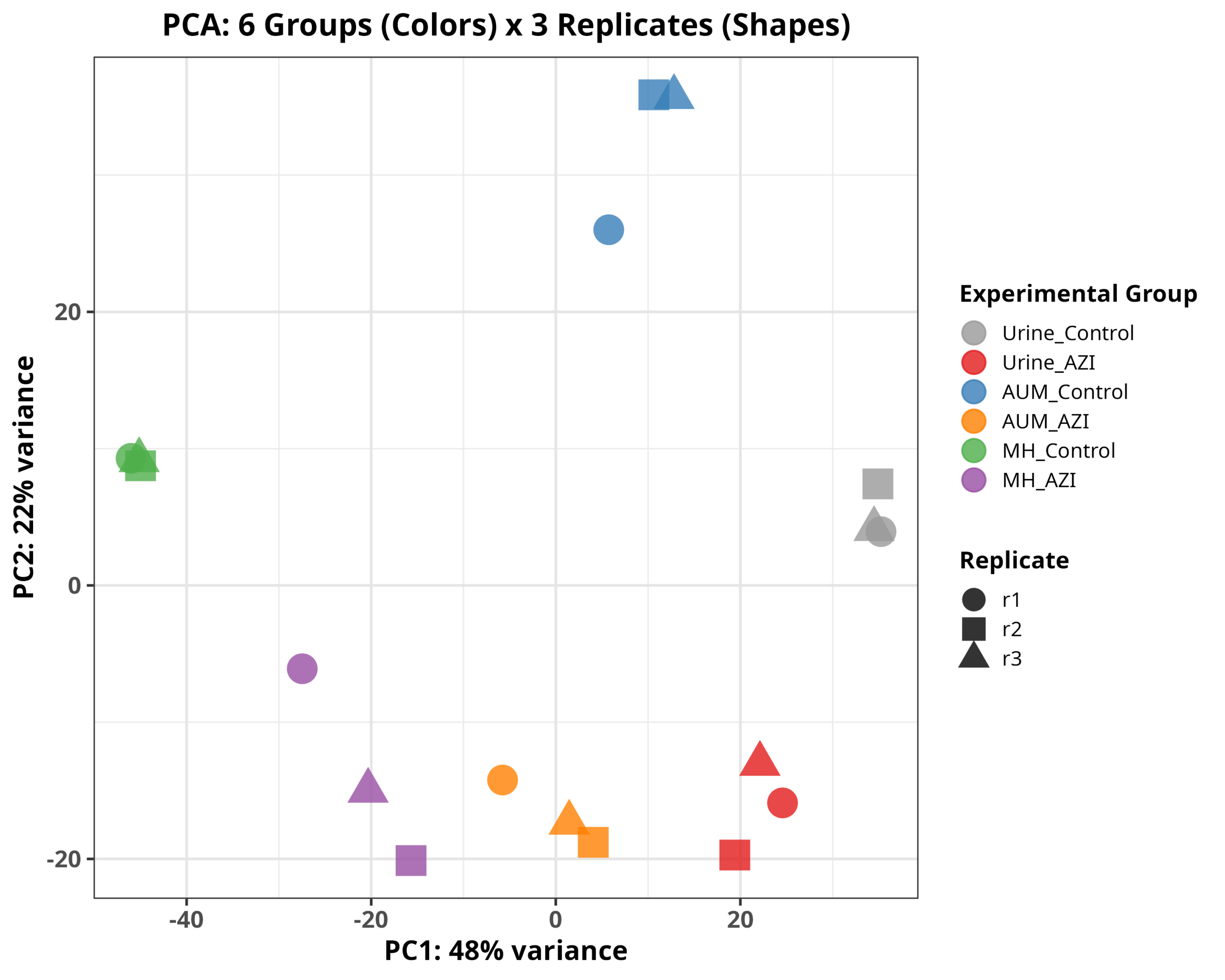
p <- ggplot(pca_data, aes(x = PC1, y = PC2, color = Group, shape = replicate)) +
geom_point(size = 8, alpha = 0.8) +
scale_color_manual(values = my_colors) +
scale_shape_manual(values = c("r1" = 16, "r2" = 15, "r3" = 17)) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: 6 Groups (Colors) x 3 Replicates (Shapes)",
color = "Experimental Group",
shape = "Replicate") +
theme_bw(base_size = 16) +
theme(
axis.text = element_text(face = "bold", size = 14),
axis.title = element_text(face = "bold", size = 16),
legend.title = element_text(face = "bold", size = 14),
legend.text = element_text(size = 12),
plot.title = element_text(hjust = 0.5, face = "bold", size = 18),
panel.grid.major = element_line(color = "grey90")
) +
guides(color = guide_legend(override.aes = list(size = 6)),
shape = guide_legend(override.aes = list(size = 6)))
ggsave("PCA_Group_x_Replicate.png", p, width = 10, height = 8, dpi = 300)
# Verify the fix
print(table(pca_data$Group))
# 1. PCA Data Extraction
vsd <- vst(dds, blind = FALSE)
pca_data <- plotPCA(vsd, intgroup = c("media", "treatment", "replicate"), returnData = TRUE)
# 2. CRITICAL FIX: Clean 'media' column to remove replicate suffixes (_r1, _r2, _r3)
pca_data$media_clean <- gsub("_r[1-3]$", "", pca_data$media)
# 3. Create Group & Replicate identifiers
pca_data$Group <- paste(pca_data$media_clean, pca_data$treatment, sep = "_")
pca_data$Replicate <- sub(".*_(r\\d+)$", "\\1", pca_data$name, ignore.case = TRUE)
# Define logical ordering for consistent legend layout
group_order <- c("Urine_Control", "Urine_AZI", "AUM_Control", "AUM_AZI", "MH_Control", "MH_AZI")
pca_data$Group <- factor(pca_data$Group, levels = group_order)
pca_data$Replicate <- factor(pca_data$Replicate, levels = c("r1", "r2", "r3"))
# Generate SampleID with explicit ordering (Group1:r1,r2,r3 -> Group2:r1,r2,r3 ...)
pca_data$SampleID <- factor(paste(pca_data$Group, pca_data$Replicate, sep = "_"),
levels = paste(rep(group_order, each = 3),
rep(c("r1", "r2", "r3"), times = 6),
sep = "_"))
# 4. Define 18 Colors (6 groups × 3 progressive shades)
sample_colors <- c(
"Urine_Control_r1" = "#1B5E77", "Urine_Control_r2" = "#1B9E77", "Urine_Control_r3" = "#66CCB5",
"Urine_AZI_r1" = "#B34A00", "Urine_AZI_r2" = "#D95F02", "Urine_AZI_r3" = "#F2A65A",
"AUM_Control_r1" = "#4A3D7A", "AUM_Control_r2" = "#7570B3", "AUM_Control_r3" = "#B3B0D9",
"AUM_AZI_r1" = "#B31A6A", "AUM_AZI_r2" = "#E7298A", "AUM_AZI_r3" = "#F285B8",
"MH_Control_r1" = "#4A7A15", "MH_Control_r2" = "#66A61E", "MH_Control_r3" = "#A3D66B",
"MH_AZI_r1" = "#7A5A15", "MH_AZI_r2" = "#A6761D", "MH_AZI_r3" = "#D6B86B"
)
percent_var <- round(100 * attr(pca_data, "percentVar"))
# 5. Plotting
p <- ggplot(pca_data, aes(x = PC1, y = PC2, color = SampleID)) +
geom_point(size = 5, shape = 16) +
scale_color_manual(values = sample_colors) +
labs(x = paste0("PC1: ", percent_var[1], "% variance"),
y = paste0("PC2: ", percent_var[2], "% variance"),
title = "PCA: 18 Samples (Grouped by Color Shades)",
color = "Sample ID") +
theme_bw() +
theme(
plot.background = element_rect(fill = "white", color = NA),
panel.background = element_rect(fill = "white", color = "grey85"),
panel.grid.major = element_line(color = "grey90"),
panel.grid.minor = element_blank(),
legend.position = "right",
legend.title = element_text(face = "bold", size = 11),
legend.text = element_text(size = 9),
axis.text = element_text(color = "black", size = 10),
axis.title = element_text(face = "bold", size = 11),
plot.margin = margin(0.5, 0.5, 0.5, 0.5, "cm") # Prevents legend cutoff
) +
guides(color = guide_legend(override.aes = list(size = 6), nrow = 6, title.position = "top"))
# 6. Quick validation before saving
cat("Sample mapping check:\n")
print(table(pca_data$SampleID))
# 7. Save & Display
ggsave("PCA_18_Samples_GroupedColors.png", p, width = 11, height = 8, dpi = 300)
message("✅ All 2 PCA plots saved to working directory!")