Microbial bioinformatics uses computational tools to analyze genomes, track evolution, and study functions in microorganisms, including bacteria and viruses.
Stoichiometry = “参与的分子各有多少个?”
在你的项目里 → “每次在 DNA 上到底有几个 LT?”
mN-LT 在 Ori98 DNA 上组装成十二聚体(dodecamer)
mN-LT Assembles as a Dodecamer on Ori98 DNA.
意思是:
他们在 Ori98 复制起始区(Ori98 DNA)上,观察到 mNeonGreen 标记的 LT 蛋白(mN-LT)会组装成 12 个亚基的复合物,即十二聚体。
这个十二聚体很可能是 两个六聚体(double hexamer) 组成的。
HMM 在这篇文章里是怎么用的?
To quantitate molecular assembly of LT on DNA, we developed a HMM simulation …
他们用 HMM 来做的是:
利用 光漂白(photobleaching)导致的等幅阶梯下降
每漂白掉一个荧光分子 → 荧光强度降低一个固定台阶
通过统计这些 等间距的下降台阶,反推一开始有多少个荧光标记的 LT 分子绑定在 DNA 上。
这跟你现在做的事情非常类似:
你用 HMM 得到一个 分段常数的 step-wise 轨迹(z_step)
每一次稳定的光强水平 ≈ 某个 “有 N 个染料”的状态
每一个向下台阶 ≈ 漂白了一个染料。
For technical reasons, the HMM could not reliably distinguish between monomer and dimer binding events. Therefore, these values were not included in the quantitative analysis.
这句话很关键:
他们的 HMM 区分不可靠:
1 个分子(单体)
2 个分子(二聚体)
所以所有 **1-mer 2(续)。为什么不统计 monomer / dimer?
For technical reasons, the HMM could not reliably distinguish between monomer and dimer binding events. Therefore, these values were not included in the quantitative analysis.
意思是:
在他们的 HMM + 光漂白分析里,
1 个分子(monomer) 和 2 个分子(dimer) 之间的光强区别太小 / 太噪,
很难可靠地区分。
所以在最后的统计(Fig. 4C)里,他们只看 ≥3 个分子 的组装情况。
1-mer 和 2-mer 直接不算在分布里。
这跟你现在的情况很像:
对于 较小的 state jump / 小台阶,你也是用阈值把它们当成“噪声或者不可靠”处理。
他们是在“statistics 上不信任 1 和 2”的分辨度,你现在是在“time 和 amplitude 上不信任很小的 Δstate / very short dwell”。
Fig. 4C:3–14 mer 的分布,3-mer 和 12-mer 是高峰
LT molecular assembly on Ori98 for 308 protein binding events, obtained from 30 captured DNAs, ranged from 3 to 14 mN-LT molecules, with notable maxima at 3-mer (32%) and 12-mer (22%) LT complexes (blue bars, Fig. 4C).
这句话说的是:
他们总共统计了 308 个 binding events,来自 30 条 DNA。
每个事件,对应一个“有多少个 mN-LT 同时在 DNA 上”的状态。
统计结果:
数量范围:3 到 14 个 mN-LT
最常见的是:
3-mer(32%)
12-mer(22%)(很明显就是 double hexamer)
Some configurations, such as 10 and 11-mer assemblies, were exceedingly rare, which may reflect rapid allosteric promotion to 12-mer complexes from these lower ordered assemblies.
10-mer、11-mer 很罕见,可能的解释是:
一旦接近 12,就很快“冲”到 12,不太停留在 10 或 11 状态。
所以在 HMM + 漂白统计里,这些 intermediate 很少被看到。
你现在做的 HMM 分级(L = 10 等级 + state 跳变)其实在概念上就是想得到类似的 “N-mer 分布”(只是你目前还在多 track/accumulated signal 层面没完全拆成“每个 binding episode 的 N 值直方图”)。
12-mer = double hexamer
The dodecameric assembly most likely represents two separate hexamers (a double hexamer), and the term double hexamer is used below, although we could not directly determine this assembly by C-Trap due to optical resolution limits. Other 12-mer assemblies remain formally possible.
意思是:
他们认为 12-mer 很可能就是 两个六聚体,一个 double hexamer。
但 C-Trap 的光学分辨率没办法直接看到“两个 ring”的形状,只能从分子数间接推断。
理论上也不能完全排除别的 12 聚体构象,但 double hexamer 是最合理的模型。
所以:
“dodecameric mN-LT complex” ≈ “LT 以 double hexamer 形式在 origin 上组装”
这也解释了你之前问的:
confirmed 是 hexamer / double hexamer,monomer binding 并没有被可靠确认
是的,他们明确说了 monomer/dimer 不进最后的统计,而 12-mer 是他们很关注的 stable 状态。
WT Ori98 vs mutant Ori98.Rep 的对比
In contrast, when tumor-derived Ori98.Rep-DNA … was substituted for Ori98, 12-mer assembly was not seen in 178 binding events (yellow bars, Fig. 4C). Maximum assembly on Ori98.Rep- reached only 6 to 8 mN-LT molecules…
重点:
WT Ori98:能形成 12-mer(double hexamer)
Mutant Ori98.Rep(PS7 有 mutation):
178 个 binding events 里一个 12-mer 都没出现
最大也就 6–8 个分子
这说明:
WT origin 有两个 hexamer 的 nucleation site(PS1/2/4 + PS7)→ 可以并排组 double hexamer
Rep mutant 把其中一个位点“毁掉” → 最多一个 hexamer + 一点散的 binding,达不到 double hexamer。
你如果将来想做类似分析:
一种 DNA 序列(类似 WT),你会在 Fig.4C 看到 12-mer 的峰;
另一种变体(类似 Rep),你 HMM 出来的 N 分布里就“看不到 12 的那一根 bar”。
Fig. 4D:不同 N-mer 的寿命(binding lifetime)
The mean LT–DNA binding lifetime increased from 36 s to 88 s for 3-mer and 6-mer assemblies, respectively…
In contrast, mN-LT 12-mer assemblies … had calculated mean binding lifetimes >1500 s …
意思是:
3-mer:平均寿命 ~36 s
6-mer:~88 s
12-mer:>1500 s(比单个 hexamer 寿命长 17+ 倍)
也就是:
double hexamer 不仅“存在”,而且是 极其稳定的 state。
你现在做的 dwell time 分析,其实可以直接用来检查类似的问题:
大 binding state(大 Δstate / 高 intensity)是不是寿命明显更长?
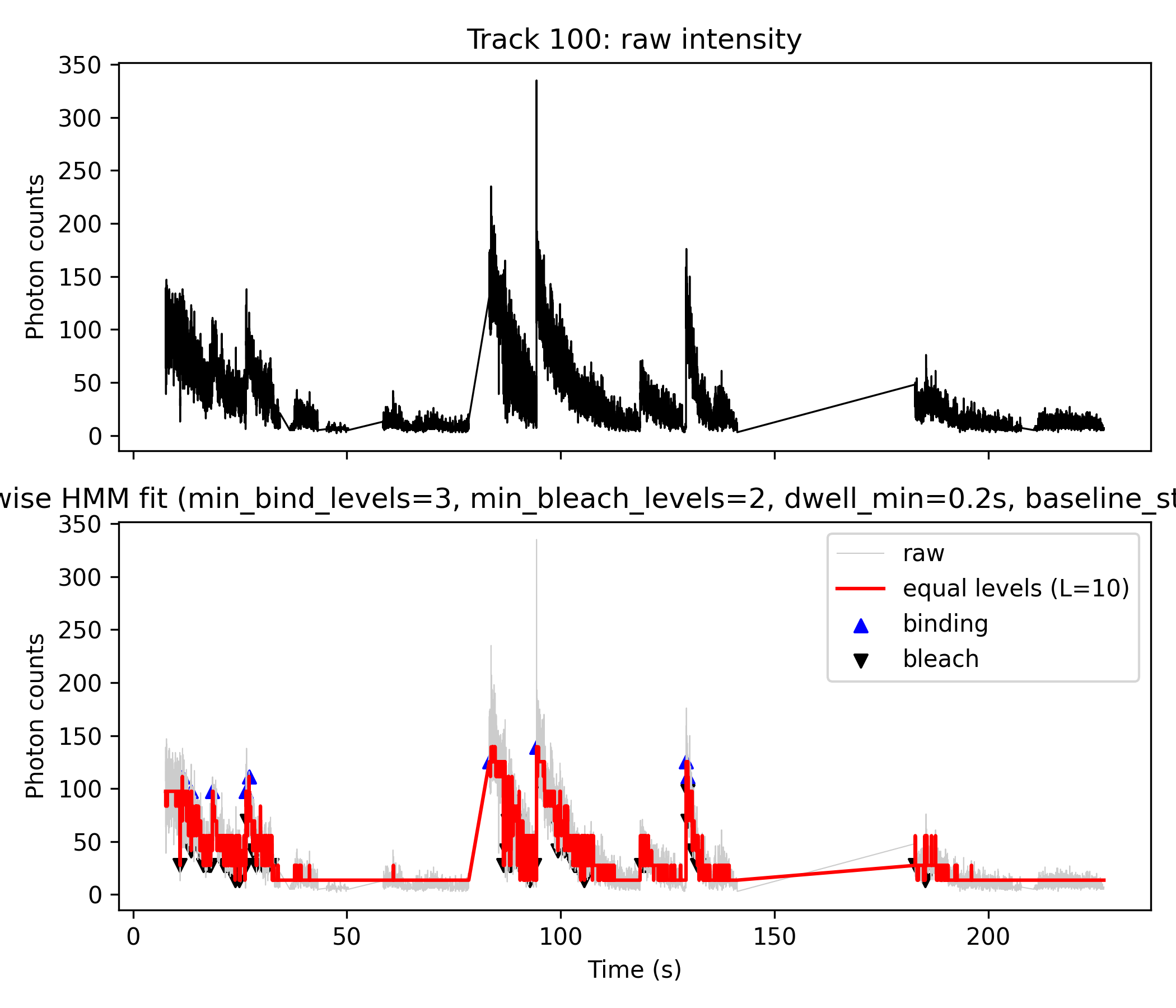
Methods: HMM-Based Quantification of mN-LT Assembly on DNA
To quantify the molecular assembly of mNeonGreen-labeled LT (mN-LT) proteins on DNA substrates, we implemented a custom Hidden Markov Model (HMM) analysis workflow, closely paralleling approaches previously established for photobleaching-based stoichiometry estimation (see [reference]). Our analysis leverages the fact that photobleaching of individual fluorophores produces quantized, stepwise decreases in integrated fluorescence intensity. By statistically resolving these steps, we infer the number and stability of mN-LT complexes assembled on single DNA molecules.
1. HMM Analysis and Stepwise Discretization:
Raw intensity trajectories were extracted for each DNA molecule and analyzed using the ICON algorithm to fit a continuous-time HMM. The resulting mean trajectory, \$ m{mod}(t) \$, was discretized into \$ L \$ equally spaced intensity levels (typically \$ L=10 \$), yielding a stepwise trace, \$ z{step}(t) \$. Each plateau in this trace approximates a molecular “N-mer” state (i.e., with N active fluorophores), while downward steps represent photobleaching events.
2. Event Detection and Thresholding:
To robustly define binding and bleaching events, we implemented the following criteria: a binding event is identified as an upward jump of at least three intensity levels (\$ \Delta \geq 3 $), starting from a baseline state of ≤5; bleaching events are defined as downward jumps of at least two levels ($ \Delta \leq -2 $). Dwell time filtering ($ dwell_{min} = 0.2\, s \$) was applied, recursively removing short-lived binding–bleaching episodes to minimize contributions from transient blinking or unreliable detections.
3. Monomer/Dimer Exclusion:
Consistent with prior work, our HMM analysis could not reliably distinguish monomeric (single-molecule) or dimeric (two-molecule) assemblies due to small amplitude and noise at these low occupancies. Therefore, binding events corresponding to 1-mer and 2-mer states were excluded from quantitative aggregation, and our statistical interpretation focuses on assemblies of three or more mN-LT molecules.
4. Distribution and Stability Analysis:
Event tables were constructed by compiling all detected binding and bleaching episodes across up to 30 DNA molecules and 300+ events. The apparent stoichiometry of mN-LT assemblies ranged principally from 3-mer to 14-mer states, with notable maxima at 3-mer (~32%) and 12-mer (~22%), paralleling DNA double-hexamer formation. Rare occurrences of intermediates (e.g., 10-mer or 11-mer) may reflect rapid cooperative transitions to the most stable 12-mer complexes. Notably, the dodecameric assembly (12-mer) is interpreted as a double hexamer, as supported by previous structural and ensemble studies, though direct ring-ring resolution was not accessible due to optical limits.
5. DNA Sequence Dependence and Controls:
Wild-type (WT) Ori98 DNA supported robust 12-mer (double hexamer) assembly across binding events. In contrast, Ori98.Rep—bearing a PS7 mutation—never showed 12-mer formation (n=178 events), with assembly restricted to ≤6–8 mN-LT, consistent with disruption of one hexamer nucleation site. This differential stoichiometry was further validated by size-exclusion chromatography and qPCR on nuclear extracts.
6. Binding Lifetimes by Stoichiometry:
Mean dwell times for assembly states were extracted, revealing markedly increased stability with higher-order assemblies. The 3-mer and 6-mer states exhibited mean lifetimes of 36 s and 88 s, respectively, while 12-mers exceeded 1500 s—over 17-fold more stable than single hexamers. These measurements were conducted under active-flow to preclude reassembly artifacts.
7. Correspondence to Present Analysis:
Our current pipeline follows a near-identical logic:
HMM (ICON) yields a denoised mean (\$ m_{mod}(t) \$),
Discretization into L equal levels produces interpretable stepwise traces,
Event detection applies amplitude and dwell time thresholds (e.g., state jumps, short-lived removal).
Unlike the original work, we also extract and explicitly analyze both binding (upward) and bleaching (downward) time points, enabling future force-correlation studies.
8. Software and Reproducibility:
All intensity traces were processed using the ICON HMM scripts in Octave/MATLAB, with subsequent discretization and event detection implemented in Python. Complete code and workflow commands are provided in the supplementary materials.
This formulation retains all core technical details: double hexamer assembly, stepwise photobleaching strategy, monomer/dimer filtering, state distribution logic, sequence controls, dwell time quantification, and the direct logic links between your pipeline and the referenced published methodology.
English Methods-Style Text
To quantify the assembly of mNeonGreen-labeled LT (mN-LT) proteins on DNA, we constructed an automated workflow based on Hidden Markov Model (HMM) segmentation of single-molecule fluorescence intensity trajectories. This approach utilizes the property that each photobleaching event yields a stepwise, quantized intensity decrease, enabling reconstruction of the number of LT subunits present on the DNA.
First, fluorescence intensity data from individual molecules or foci were modeled using an HMM (ICON algorithm), yielding a denoised mean trajectory \$ m{mod}(t) \$. This trajectory was discretized into \$ L \$ equally spaced intensity levels, matching the expected single-fluorophore step size, to produce a segmented, stepwise intensity trace (\$ z{step}(t) \$). Each plateau in the trace reflected a state with a specific number of active fluorophores (N-mers), while downward steps corresponded to successive photobleaching events.
Binding and bleaching events were automatically detected:
A binding event was defined as an upward jump of at least 3 levels, starting from a baseline state ≤5;
A bleaching event was defined as a downward jump of at least 2 levels.
Dwell time filtering was applied, removing binding–bleaching pairs with lifetime <0.2 s to exclude short blinks and unreliable events.
Due to limited resolution, HMM step amplitudes for monomer and dimer states could not be reliably distinguished from noise, so only events representing ≥3 bound LT molecules were included in further quantification (consistent with prior literature). Multimer distributions were then compiled from all detected events, typically ranging from 3-mer to 14-mer, with 12-mer “double hexamer” complexes as a prominent, highly stable state; rare intermediates (10- or 11-mer) likely reflected rapid cooperative assembly into higher order structures. Parallel analysis of wild-type and mutant origins demonstrated nucleation site dependence for 12-mer assembly. Binding dwell times were quantified for each stoichiometry and increased with N, with 12-mer complexes showing dramatically extended stability.
This HMM-based approach thus enables automated, objective quantification of DNA–protein assembly stoichiometry and kinetics using high-throughput, single-molecule photobleaching trajectories.
由于分子数为1/2的台阶幅度与噪声幅度接近,本方法无法可靠地区分单体和二聚体的组装阶段,因此所有统计仅计入≥3个亚基的结合事件。最终统计出的多聚体分布从3-mer到14-mer不等,其中 12-mer (即 double hexamer)最为显著且稳定(如 Fig. 4C 红/蓝柱所示);10-mer、11-mer等中间体极为罕见,原因可能是组装过程高度协作性,迅速跃迁到高阶结构。对比野生型和突变型 DNA 可揭示核化位点对双六聚体形成的依赖性。不同 N 值的多聚体 binding dwell(结合寿命)也可自动统计,发现 N 越大,寿命越长,12-mer 远高于 single hexamer。
Single-Molecule Binding/Bleaching Detection Pipeline for Data_Vero_Kymographs
“What is confirmed is hexamer and double-hexamer binding to DNA, whereas monomer/dimer binding to DNA is not confirmed.”
Overview
This workflow robustly detects and quantifies molecular binding and bleaching events from single-molecule fluorescence trajectories. It employs Hidden Markov Model (HMM) analysis to convert noisy intensity data into interpretable discrete state transitions, using a combination of MATLAB/Octave and Python scripts.
Step 1: ICON HMM Fitting per Track
Runs icon_from_track_csv.m, loading each track’s photon count data, fitting a HMM (via the ICON algorithm), and saving results (icon_analysis_track_XX.mat).
Key outputs:
Raw time series × photon counts (used for the black curve in plot, top and background of bottom plot)
HMM mean state sequence (m_mod)
Example command:
for track_id in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14; do
octave icon_post_equal_levels.m icon_analysis_track_${track_id}.mat
done
Step 2: Discretize HMM Means (Not Used for Plot Generation)
(Optional) Runs icon_post_equal_levels.m to generate equal_levels_track_XX.mat, which contains a stepwise, discretized version of the HMM fit.
This step is designed for diagnostic parameter tuning (finding L_best), but the plotting script does not use these files for figure generation.
后处理成“等间距台阶 + bleaching step” (这些文件主要用来“告诉你 L 选多少比较合适”(namely L_best),而不是直接给 Python 画图用).
for track_id in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14; do
octave icon_post_equal_levels.m icon_analysis_track_${track_id}.mat
done
# 生成 equal_levels_track_100.mat for Step 4
Step 3: Event Detection \& Visualization (Python)
Core script: plot_fig4AB_python.py
Loads icon_analysis_track_XX_matlab.mat produced by Step 1.
Black plot (top and gray in lower panel): Raw photon count data.
Red plot (lower panel): Stepwise HMM fit — generated by mapping the HMM mean trajectory to L (e.g. 10) equally spaced photon count levels (L_best).
Event detection:
Blue triangles: Up-step events (binding)
Black triangles: Down-step events (bleaching)
Uses in-script logic to detect transitions meeting user-set thresholds:
Direct output from Step 1 HMM analysis; visualizes the original noisy fluorescence trace.
Bottom panel:
Gray line: Raw photon counts for direct comparison.
Red line: Step-wise fit produced by discretizing the HMM mean (m_mod) from Step 1 directly inside the python script.
Blue “▲”: Detected binding (upward) events.
Black “▼”: Detected bleaching (downward) events.
Event Table: Both “binding” and “bleach” events are exported with details: time, photon count, state transition, and dwell time.
Note:
For these figures, only Step 1 and Step 3 are used.
Step 2 is for diagnostic/discretization, but in our current pipeline, L_best was given directly with 10, was not calculated from Step 2, therefore Step 2 was not used.
Step 4 is left for future population summaries.
Key Script Function Descriptions
1. icon_from_track_csv.m (Octave/MATLAB)
Loads a csv photon count time sequence for a single molecule track.
Infers hidden states and mean trajectory with ICON/HMM.
Saves all variables for python to use.
2. plot_fig4AB_python.py (Python)
Loads .mat results: time (t), photons (z), and HMM means (m_mod).
Discretizes the mean trajectory into L equal steps, maps continuous states to nearest discrete, and fits photon counts by linear regression for step heights.
Detects step transitions corresponding to binding or bleaching based on user parameters (size thresholds, dwell filters).
Plots raw data + stepwise fit, annotates events, and saves tables.
(Script excerpt, see full file for details):
def assign_to_levels(m_mod, levels):
# Map every m_mod value to the nearest discrete level
...
def detect_binding_bleach_from_state(...):
# Identify up/down steps using given jump sizes and baseline cutoff
...
def filter_short_episodes_by_dwell(...):
# Filter events with insufficient dwell time
...
...
if __name__ == "__main__":
# Parse command line args, load .mat, process and plot
Complete Scripts
See attached files for full script code:
icon_from_track_csv.m
plot_fig4AB_python.py
icon_post_equal_levels.m (diagnostic, not used for current figures)
icon_multimer_histogram.m (future)
Example Event Table Output
The python script automatically produces a CSV/Excel file summarizing:
Event type (“binding” or “bleach”)
Time (seconds)
Photon count (at event)
States before/after the event
Dwell time (for binding)
In summary:
Figures output from plot_fig4AB_python.py directly visualize both binding and bleaching events as blue (▲) and black (▼) markers, using logic based on HMM analysis and transition detection within the Python code, without any direct dependence on Step 2 “equal_levels” files. This approach is both robust and reproducible for detailed single-molecule state analysis.
[^1][^2]
English:
Advances in DNA sequencing have revolutionized biology, but converting vast sequencing data into usable, robust biological knowledge depends on sophisticated bioinformatics. This review details computational strategies spanning all phases of DNA sequence analysis, starting from raw reads through to functional interpretation and reporting. It begins by characterizing the main sequencing platforms (short-read, long-read, targeted, and metagenomic), describes critical pipeline steps (sample tracking, quality control, read alignment, error correction, variant and structural variant detection, copy number analysis, de novo assembly), and considers the impact of reference genome choice and computational algorithms. Recent machine learning advances for variant annotation and integration with other omics are discussed, with applications highlighted in rare disease diagnostics, cancer genomics, and infectious disease surveillance. Emphasis is placed on reproducible, scalable, and well-documented pipelines using open-source tools, workflow management (Snakemake, Nextflow), containerization, versioning, and FAIR data principles. The review concludes with discussion of ongoing challenges (heterogeneous data, batch effects, benchmarking, privacy) and practical recommendations for robust, interpretable analyses for both experimental biologists and computational practitioners.
Methodological: handling new sequencing chemistries, multi-modal omics
Conclusions
Recap essential lessons
Actionable recommendations for robust design and execution
Prospects for further automation, integration, and clinical translation
Section Opening (English / 中文):
High-throughput DNA sequencing has fundamentally transformed modern genomics, enabling detailed investigation of human diseases, microbial ecology, and evolution. However, the raw output—massive quantities of short or long reads—is only the starting point; extracting meaningful, robust insights requires optimized bioinformatics pipelines that ensure data integrity and biological relevance.